178/*
179 * If nxtlist is not NULL, it is partitioned as follows.
180 * Any of the partitions might be empty, in which case the
181 * pointer to that partition will be equal to the pointer for
182 * the following partition. When the list is empty, all of
183 * the nxttail elements point to the ->nxtlist pointer itself,
184 * which in that case is NULL.
185 *
186 * [nxtlist, *nxttail[RCU_DONE_TAIL]):
187 * Entries that batch # <= ->completed
188 * The grace period for these entries has completed, and
189 * the other grace-period-completed entries may be moved
190 * here temporarily in rcu_process_callbacks().
191 * [*nxttail[RCU_DONE_TAIL], *nxttail[RCU_WAIT_TAIL]):
192 * Entries that batch # <= ->completed - 1: waiting for current GP
193 * [*nxttail[RCU_WAIT_TAIL], *nxttail[RCU_NEXT_READY_TAIL]):
194 * Entries known to have arrived before current GP ended
195 * [*nxttail[RCU_NEXT_READY_TAIL], *nxttail[RCU_NEXT_TAIL]):
196 * Entries that might have arrived after current GP ended
197 * Note that the value of *nxttail[RCU_NEXT_TAIL] will
198 * always be NULL, as this is the end of the list.
199 */
1308 __rcu_process_callbacks(struct rcu_state *rsp,struct rcu_data *rdp) 1309{ 1310unsignedlong flags; 1311 1312 WARN_ON_ONCE(rdp->beenonline ==0); 1313 1314/*
1315 * If an RCU GP has gone long enough, go check for dyntick
1316 * idle CPUs and, if needed, send resched IPIs.
1317 */ 1318if(ULONG_CMP_LT(ACCESS_ONCE(rsp->jiffies_force_qs), jiffies)) 1319 force_quiescent_state(rsp,1); 1320 1321/*
1322 * Advance callbacks in response to end of earlier grace
1323 * period that some other CPU ended.
1324 */ 1325 rcu_process_gp_end(rsp, rdp); 1326 1327/* Update RCU state based on any recent quiescent states. */ 1328 rcu_check_quiescent_state(rsp, rdp); 1329 1330/* Does this CPU require a not-yet-started grace period? */ 1331if(cpu_needs_another_gp(rsp, rdp)){ 1332 raw_spin_lock_irqsave(&rcu_get_root(rsp)->lock, flags); 1333 rcu_start_gp(rsp, flags);/* releases above lock */ 1334} 1335 1336/* If there are callbacks ready, invoke them. */ 1337 rcu_do_batch(rsp, rdp); 1338}
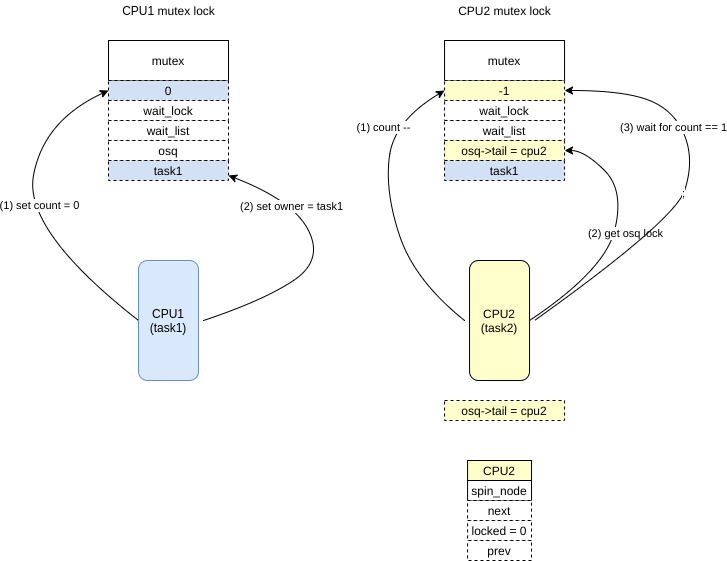
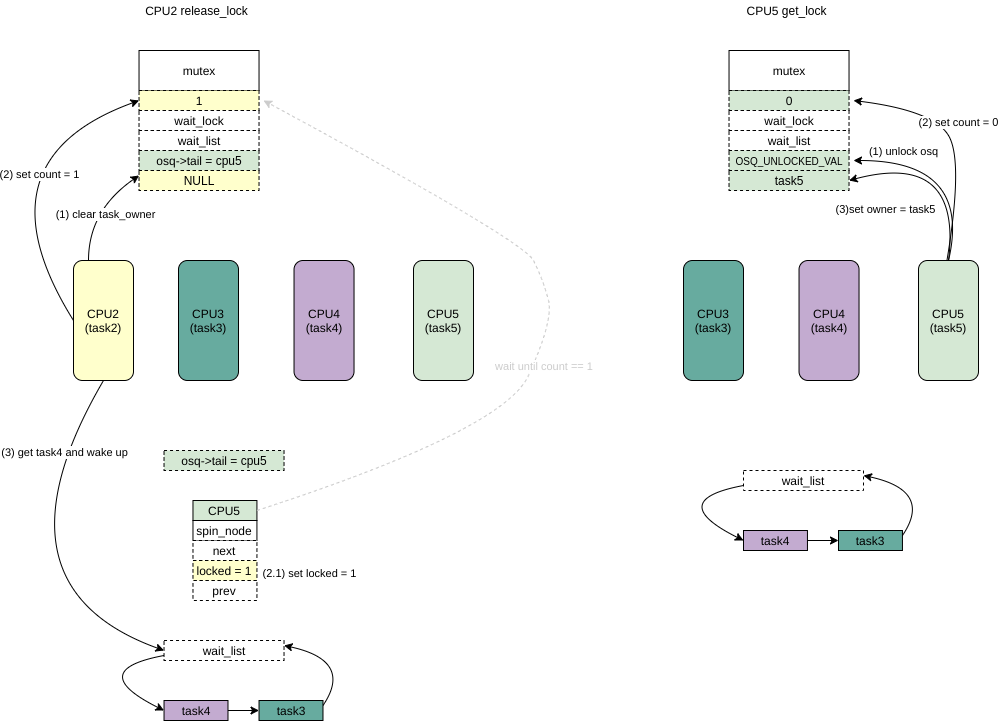
/*
* Once more, try to acquire the lock. Only try-lock the mutex if
* it is unlocked to reduce unnecessary xchg() operations.
*/ if(!mutex_is_locked(lock)&&(atomic_xchg(&lock->count,0)==1)) goto skip_wait;
/* add waiting tasks to the end of the waitqueue (FIFO): */ /* 加入到waiter list中 */
list_add_tail(&waiter.list,&lock->wait_list);
waiter.task= task;
lock_contended(&lock->dep_map, ip);
for(;;){ /*
* Lets try to take the lock again - this is needed even if
* we get here for the first time (shortly after failing to
* acquire the lock), to make sure that we get a wakeup once
* it's unlocked. Later on, if we sleep, this is the
* operation that gives us the lock. We xchg it to -1, so
* that when we release the lock, we properly wake up the
* other waiters. We only attempt the xchg if the count is
* non-negative in order to avoid unnecessary xchg operations:
*/ if(atomic_read(&lock->count)>=0&& (atomic_xchg(&lock->count,-1)==1)) break;
/*
* got a signal? (This code gets eliminated in the
* TASK_UNINTERRUPTIBLE case.)
*/ if(unlikely(signal_pending_state(state, task))){
ret =-EINTR; goto err; }
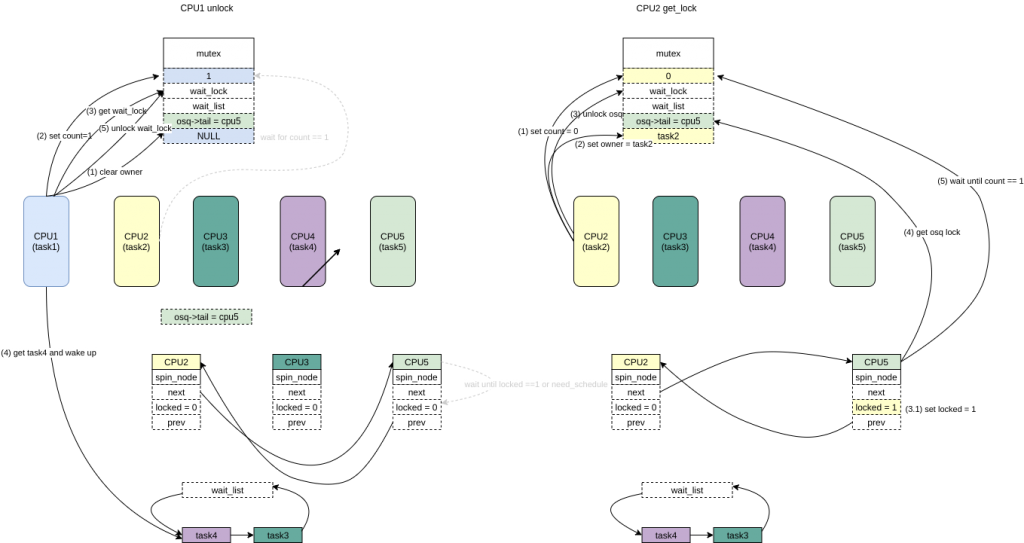
/* didn't get the lock, go to sleep: */
spin_unlock_mutex(&lock->wait_lock, flags); /* 主动调度 */
schedule_preempt_disabled();
spin_lock_mutex(&lock->wait_lock, flags); } /* 到这里说明获得了该锁 */
__set_task_state(task, TASK_RUNNING);
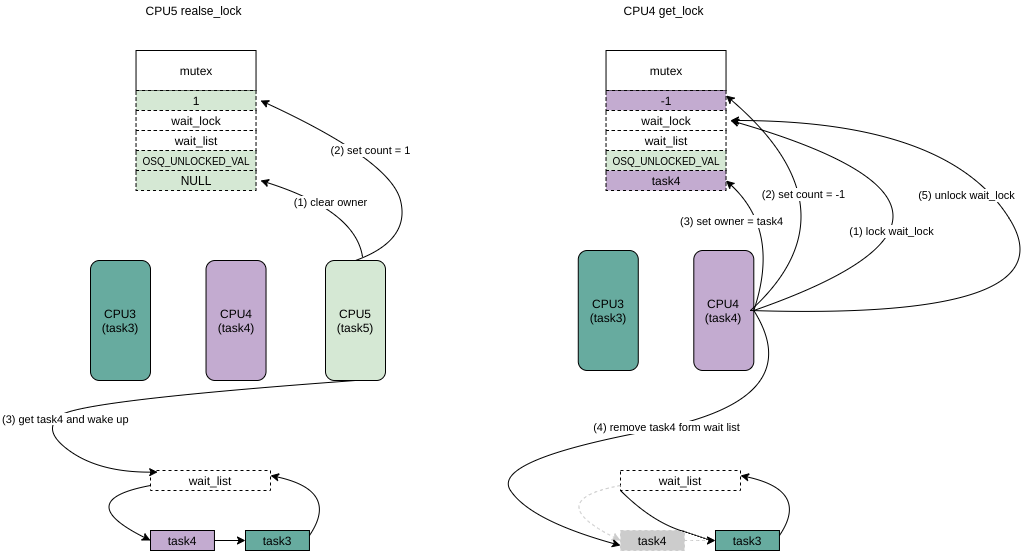
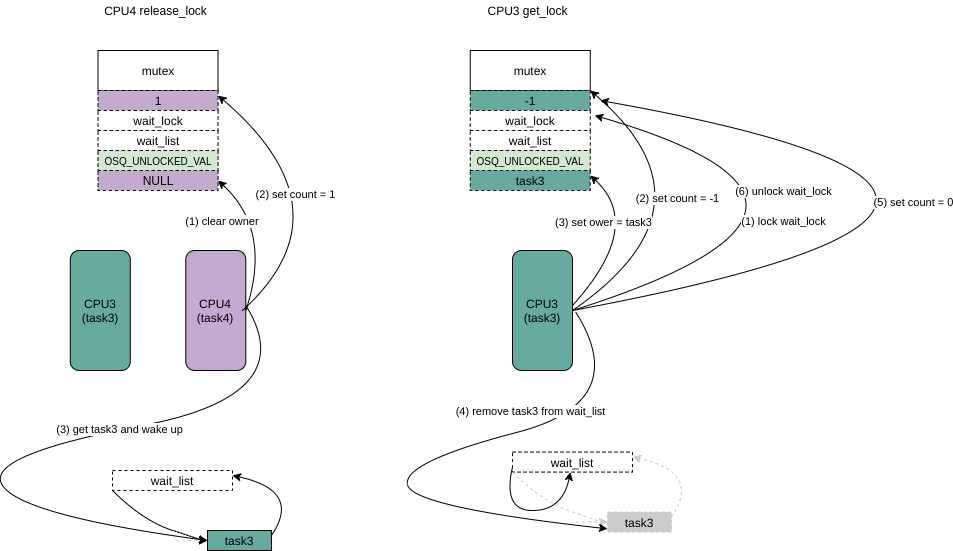
mutex_remove_waiter(lock,&waiter, current_thread_info()); /* set it to 0 if there are no waiters left: */ if(likely(list_empty(&lock->wait_list))) /* 这里因为前面的会把lock->count 直接写入为 -1, 所以如果没有其他在wait_list的人直接设置为 0 */
atomic_set(&lock->count,0);
debug_mutex_free_waiter(&waiter);
skip_wait: /* got the lock - cleanup and rejoice! */
lock_acquired(&lock->dep_map, ip);
mutex_set_owner(lock);
/*
* Optimistic spinning.
*
* We try to spin for acquisition when we find that the lock owner
* is currently running on a (different) CPU and while we don't
* need to reschedule. The rationale is that if the lock owner is
* running, it is likely to release the lock soon.
*
* Since this needs the lock owner, and this mutex implementation
* doesn't track the owner atomically in the lock field, we need to
* track it non-atomically.
*
* We can't do this for DEBUG_MUTEXES because that relies on wait_lock
* to serialize everything.
*
* The mutex spinners are queued up using MCS lock so that only one
* spinner can compete for the mutex. However, if mutex spinning isn't
* going to happen, there is no point in going through the lock/unlock
* overhead.
*
* Returns true when the lock was taken, otherwise false, indicating
* that we need to jump to the slowpath and sleep.
*/ static bool mutex_optimistic_spin(struct mutex *lock, struct ww_acquire_ctx *ww_ctx,const bool use_ww_ctx) { struct task_struct *task = current;
/*
* In order to avoid a stampede of mutex spinners trying to
* acquire the mutex all at once, the spinners need to take a
* MCS (queued) lock first before spinning on the owner field.
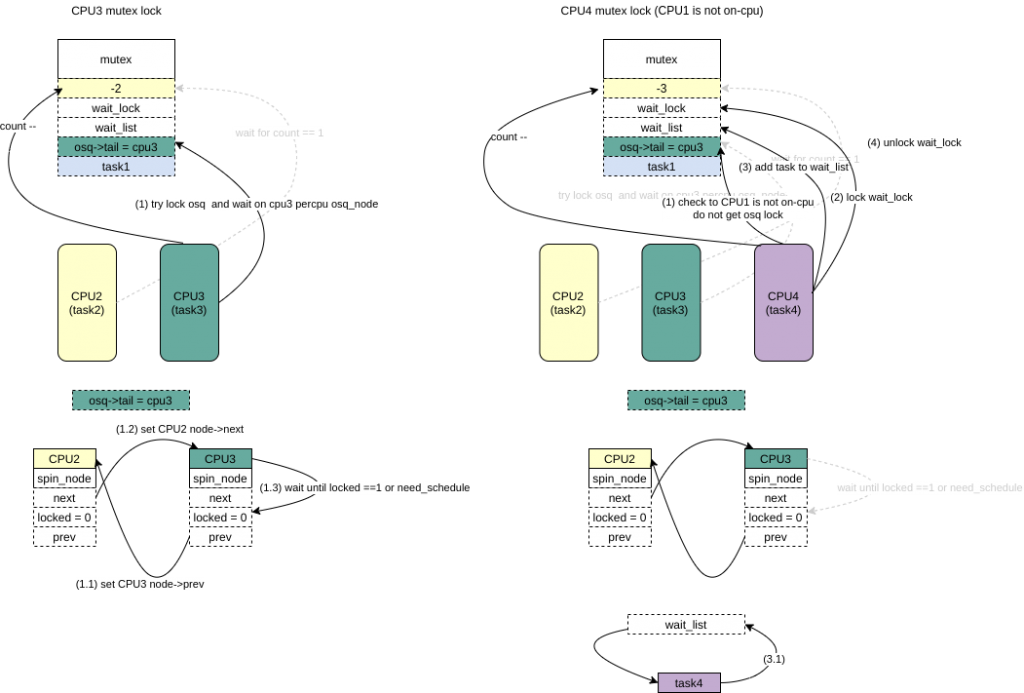
*/ if(!osq_lock(&lock->osq)) goto done;
while(true){ struct task_struct *owner;
if(use_ww_ctx && ww_ctx->acquired >0){ struct ww_mutex *ww;
ww = container_of(lock,struct ww_mutex, base); /*
* If ww->ctx is set the contents are undefined, only
* by acquiring wait_lock there is a guarantee that
* they are not invalid when reading.
*
* As such, when deadlock detection needs to be
* performed the optimistic spinning cannot be done.
*/ if(READ_ONCE(ww->ctx)) break; }
/*
* If there's an owner, wait for it to either
* release the lock or go to sleep.
*/
owner = READ_ONCE(lock->owner); if(owner &&!mutex_spin_on_owner(lock, owner)) break;
/* Try to acquire the mutex if it is unlocked. */ if(mutex_try_to_acquire(lock)){
lock_acquired(&lock->dep_map, ip);
/*
* When there's no owner, we might have preempted between the
* owner acquiring the lock and setting the owner field. If
* we're an RT task that will live-lock because we won't let
* the owner complete.
*/ if(!owner &&(need_resched()|| rt_task(task))) break;
/*
* The cpu_relax() call is a compiler barrier which forces
* everything in this loop to be re-loaded. We don't need
* memory barriers as we'll eventually observe the right
* values at the cost of a few extra spins.
*/
cpu_relax_lowlatency(); }
osq_unlock(&lock->osq);
done: /*
* If we fell out of the spin path because of need_resched(),
* reschedule now, before we try-lock the mutex. This avoids getting
* scheduled out right after we obtained the mutex.
*/ if(need_resched()){ /*
* We _should_ have TASK_RUNNING here, but just in case
* we do not, make it so, otherwise we might get stuck.
*/
__set_current_state(TASK_RUNNING);
schedule_preempt_disabled(); }
/*
* Normally @prev is untouchable after the above store; because at that
* moment unlock can proceed and wipe the node element from stack.
*
* However, since our nodes are static per-cpu storage, we're
* guaranteed their existence -- this allows us to apply
* cmpxchg in an attempt to undo our queueing.
*/
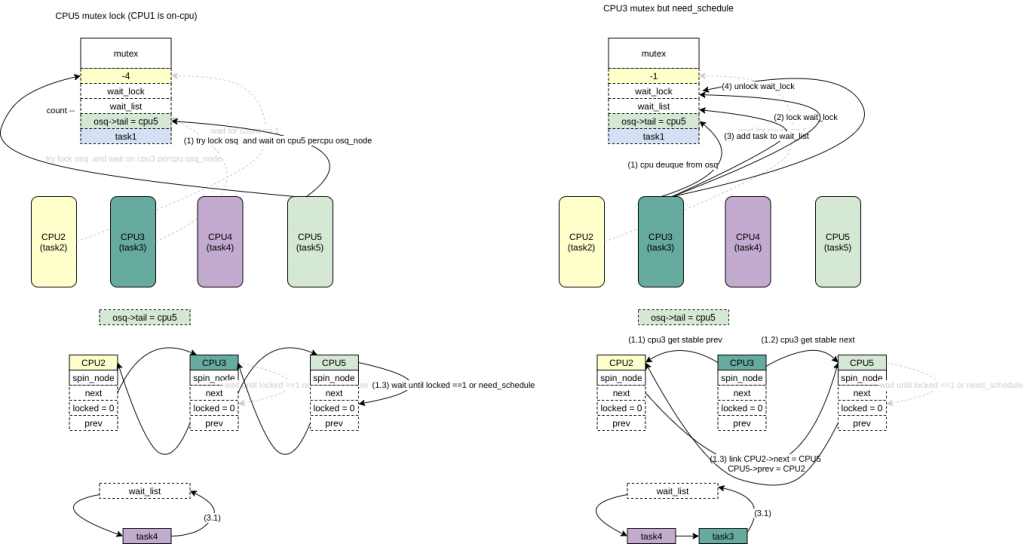
/* 等待自己的locked 被设置 */ while(!READ_ONCE(node->locked)){ /*
* If we need to reschedule bail... so we can block.
*/ /* 这里是和qspinlock的区别,这里可能会调度出去 */ if(need_resched()) goto unqueue;
cpu_relax_lowlatency(); } returntrue;
unqueue: /*
* Step - A -- stabilize @prev
*
* Undo our @prev->next assignment; this will make @prev's
* unlock()/unqueue() wait for a next pointer since @lock points to us
* (or later).
*/
/*
* We can only fail the cmpxchg() racing against an unlock(),
* in which case we should observe @node->locked becomming
* true.
*/ if(smp_load_acquire(&node->locked)) returntrue;
cpu_relax_lowlatency();
/*
* Or we race against a concurrent unqueue()'s step-B, in which
* case its step-C will write us a new @node->prev pointer.
*/
prev = READ_ONCE(node->prev); }
/*
* Step - B -- stabilize @next
*
* Similar to unlock(), wait for @node->next or move @lock from @node
* back to @prev.
*/
next = osq_wait_next(lock, node, prev); if(!next) returnfalse;
/*
* Step - C -- unlink
*
* @prev is stable because its still waiting for a new @prev->next
* pointer, @next is stable because our @node->next pointer is NULL and
* it will wait in Step-A.
*/
/*
* Get a stable @node->next pointer, either for unlock() or unqueue() purposes.
* Can return NULL in case we were the last queued and we updated @lock instead.
*/ staticinlinestruct optimistic_spin_node *
osq_wait_next(struct optimistic_spin_queue *lock, struct optimistic_spin_node *node, struct optimistic_spin_node *prev) { struct optimistic_spin_node *next = NULL; int curr = encode_cpu(smp_processor_id()); int old;
/*
* If there is a prev node in queue, then the 'old' value will be
* the prev node's CPU #, else it's set to OSQ_UNLOCKED_VAL since if
* we're currently last in queue, then the queue will then become empty.
*/
old = prev ? prev->cpu : OSQ_UNLOCKED_VAL;
for(;;){ if(atomic_read(&lock->tail)== curr &&
atomic_cmpxchg(&lock->tail, curr, old)== curr){ /*
* We were the last queued, we moved @lock back. @prev
* will now observe @lock and will complete its
* unlock()/unqueue().
*/ break; }
/*
* We must xchg() the @node->next value, because if we were to
* leave it in, a concurrent unlock()/unqueue() from
* @node->next might complete Step-A and think its @prev is
* still valid.
*
* If the concurrent unlock()/unqueue() wins the race, we'll
* wait for either @lock to point to us, through its Step-B, or
* wait for a new @node->next from its Step-C.
*/ if(node->next){
next = xchg(&node->next, NULL); if(next) break; }
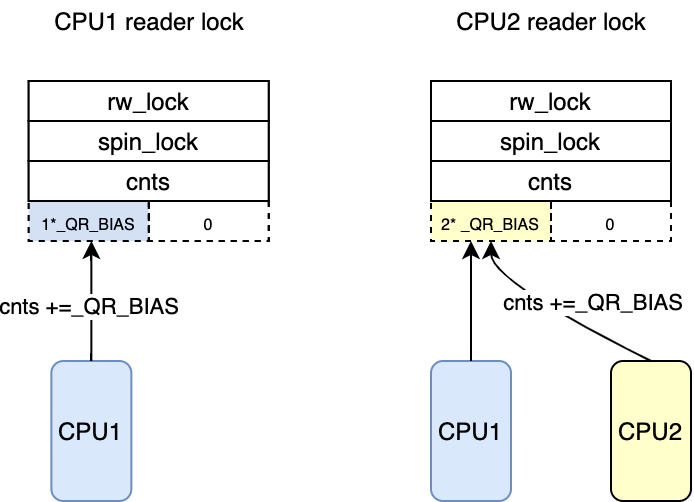
/**
* queue_read_lock_slowpath - acquire read lock of a queue rwlock
* @lock: Pointer to queue rwlock structure
*/ void queue_read_lock_slowpath(struct qrwlock *lock) {
u32 cnts;
/*
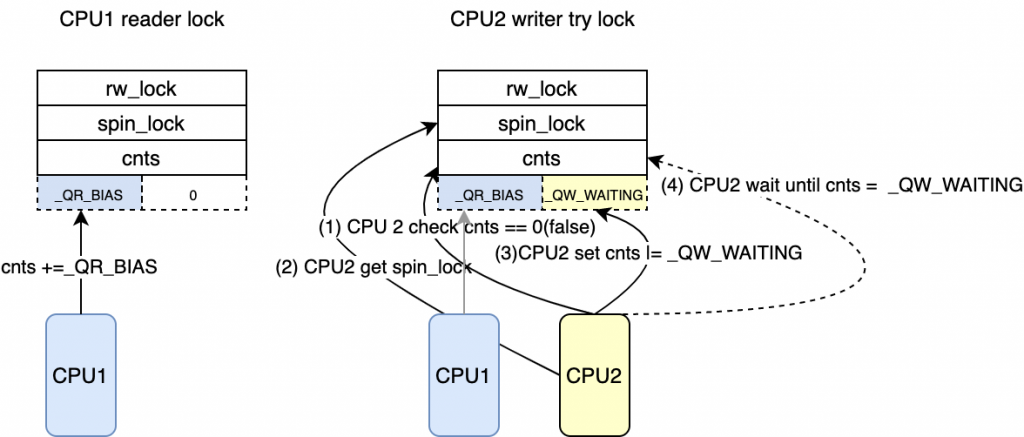
* Readers come here when they cannot get the lock without waiting
*/ if(unlikely(in_interrupt())){ /*
* Readers in interrupt context will spin until the lock is
* available without waiting in the queue.
*/
cnts = smp_load_acquire((u32 *)&lock->cnts);
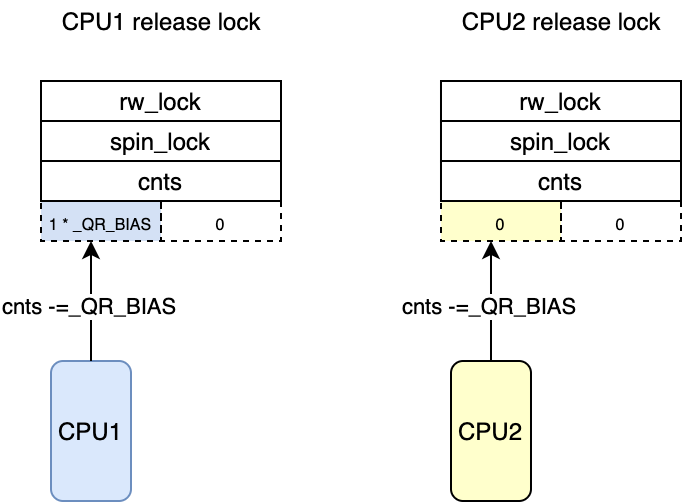
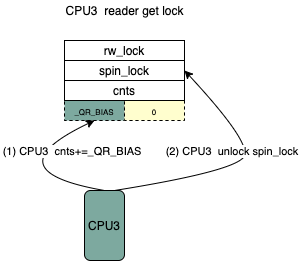
rspin_until_writer_unlock(lock, cnts); return; } /* 这里减去了_QR_BIAS 因为该cpu并没有获得reader锁 */
atomic_sub(_QR_BIAS,&lock->cnts);
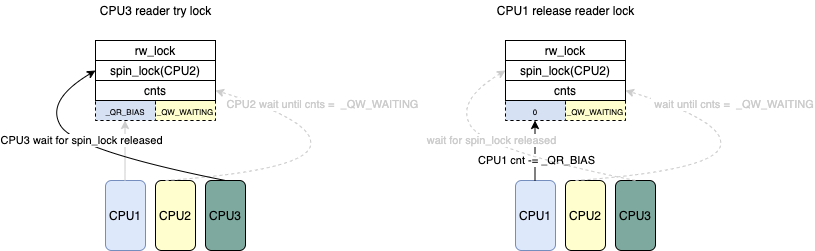
/*
* Put the reader into the wait queue
*/
arch_spin_lock(&lock->lock);
/*
* At the head of the wait queue now, wait until the writer state
* goes to 0 and then try to increment the reader count and get
* the lock. It is possible that an incoming writer may steal the
* lock in the interim, so it is necessary to check the writer byte
* to make sure that the write lock isn't taken.
*/ while(atomic_read(&lock->cnts)& _QW_WMASK)
cpu_relax_lowlatency();
/*
* Signal the next one in queue to become queue head
*/
arch_spin_unlock(&lock->lock); }
EXPORT_SYMBOL(queue_read_lock_slowpath);
/**
* queue_write_lock_slowpath - acquire write lock of a queue rwlock
* @lock : Pointer to queue rwlock structure
*/ void queue_write_lock_slowpath(struct qrwlock *lock) {
u32 cnts;
/* Put the writer into the wait queue */
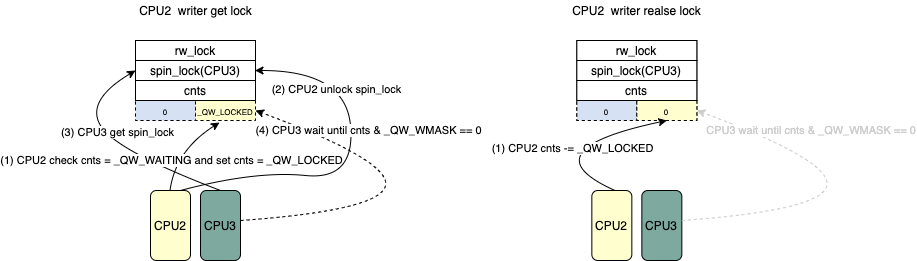
arch_spin_lock(&lock->lock);
/* 到了这里 writer 现在是head */ /* Try to acquire the lock directly if no reader is present */ if(!atomic_read(&lock->cnts)&& (atomic_cmpxchg(&lock->cnts,0, _QW_LOCKED)==0)) goto unlock;
/* 因为read_lock首先会查看lock->cnts的值,也就是如果该值没有被设置
* _QW_LOCKED 或则 _QW_WARITING, 即便是write 先拿到了锁,也可能另外的
* read 会首先获得锁,所以需要等待。 因为read_lock fast patch是直接
* 检查_QW_WMASK的值是否被设置。
* 也是有可能另外的writer_lock先获得锁,这种情况发生在
* READER-0 WRITER-0 WRITER-1
* LOCK
* try_get_lock
* UNLOCK
* LOCK
* check other
* writer get lock
*/ /*
* Set the waiting flag to notify readers that a writer is pending,
* or wait for a previous writer to go away.
*/ for(;;){
cnts = atomic_read(&lock->cnts); /* 下面等待所有其他的writer释放锁, 并且在设置了_QW_WAITING后
* 所有的在后面的read/writer都需要先lock->lock
*/ if(!(cnts & _QW_WMASK)&& (atomic_cmpxchg(&lock->cnts, cnts,
cnts | _QW_WAITING)== cnts)) break;
cpu_relax_lowlatency(); }
/* When no more readers, set the locked flag */ for(;;){
cnts = atomic_read(&lock->cnts); /* 下面的保证所有持有reader锁已经释放 */ if((cnts == _QW_WAITING)&& (atomic_cmpxchg(&lock->cnts, _QW_WAITING,
_QW_LOCKED)== _QW_WAITING)) break;
/*
* we won the trylock
*/ if(new == _Q_LOCKED_VAL) /* 这里代表上面的逻辑中,val被改为了0, 也就是锁被释放了 */ return;
/*
* we're pending, wait for the owner to go away.
*
* *,1,1 -> *,1,0
*
* this wait loop must be a load-acquire such that we match the
* store-release that clears the locked bit and create lock
* sequentiality; this is because not all clear_pending_set_locked()
* implementations imply full barriers.
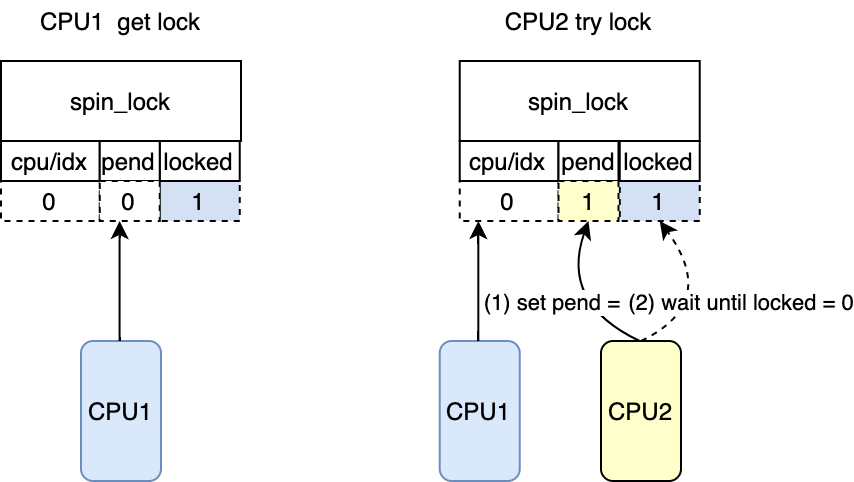
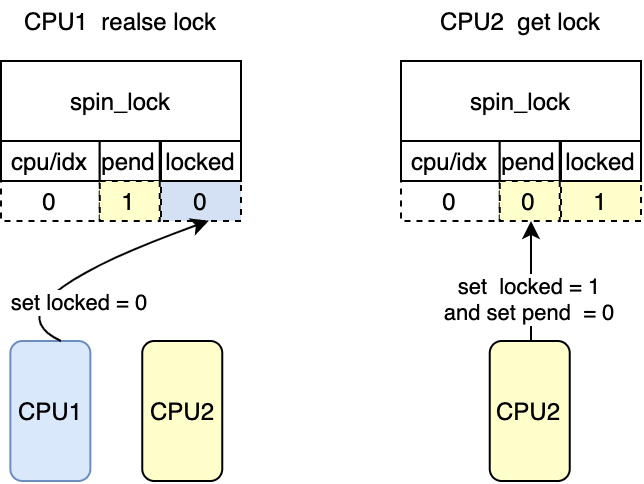
*/ while((val = smp_load_acquire(&lock->val.counter))& _Q_LOCKED_MASK) /* 等到该锁的被释放 对应图中CPU2 try lock*/
cpu_relax();
/*
* take ownership and clear the pending bit.
*
* *,1,0 -> *,0,1
*/ /* 获取该锁,对应图中CPU2 get lock */
clear_pending_set_locked(lock); return;
/*
* End of pending bit optimistic spinning and beginning of MCS
* queuing.
*/
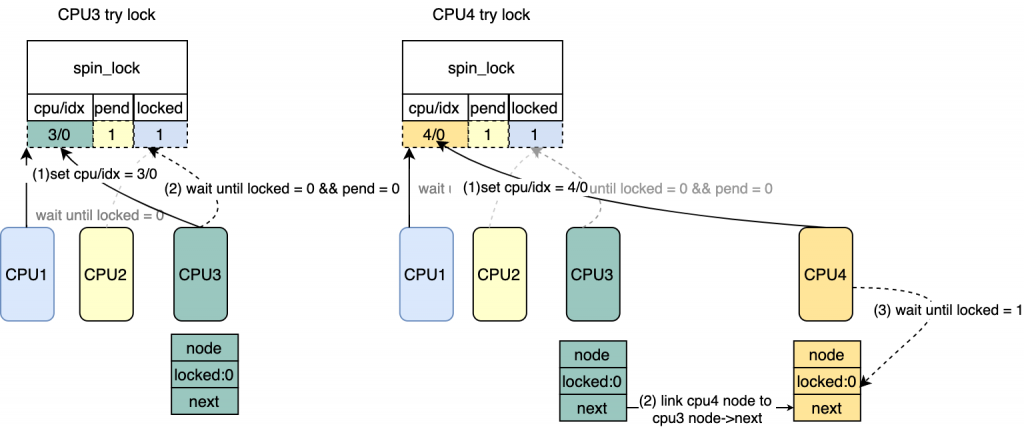
queue: /* 获得该CPU上的空闲的mcs_lock 并初始化 */
node = this_cpu_ptr(&mcs_nodes[0]);
idx = node->count++;
tail = encode_tail(smp_processor_id(), idx);
/*
* We touched a (possibly) cold cacheline in the per-cpu queue node;
* attempt the trylock once more in the hope someone let go while we
* weren't watching.
*/ /* 优化 */ if(queued_spin_trylock(lock)) goto release;
/*
* We have already touched the queueing cacheline; don't bother with
* pending stuff.
*
* p,*,* -> n,*,*
*/ /* 将tail 更新到lock tail(cpu/idx) 并且返回原来的tail
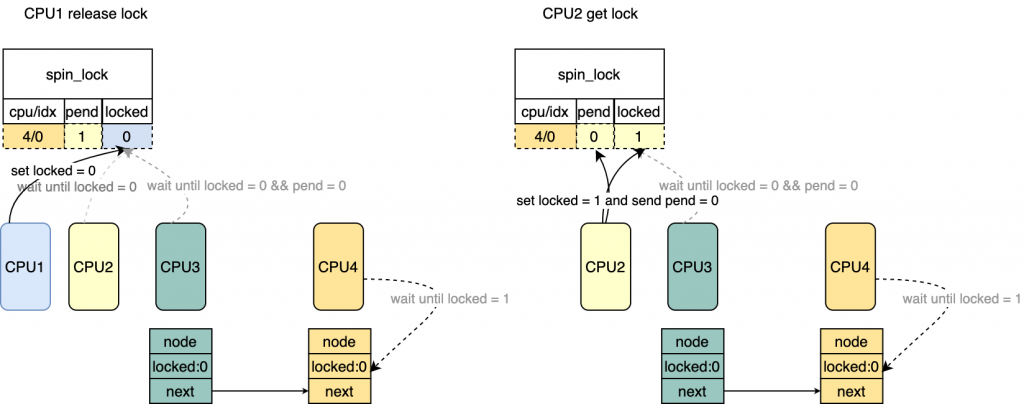
* 表示最后一个想要获得锁的CPU
* 图中CPU3 try lock的时候会写入,CPU4在try lock的时候
* 也会写入会覆盖CPU3写入的,来表示CPU4是最后一个想要
* 获得锁的。
*/
old = xchg_tail(lock, tail);
/*
* if there was a previous node; link it and wait until reaching the
* head of the waitqueue.
*/ /* 判断当前有没有多于2个CPU在等待锁,如果有把mcs链接到
* last mcs->next。
* 针对图中CPU3来说,old = 0, 说明只有一个等待锁
* 针对图中CPU4来说,old = CPU3/IDX, 需要把CPU4对应的mcs链接到CPU3/idx mcs->next
* 现在等待锁的是CPU2 CPU3。
*/ if(old & _Q_TAIL_MASK){
prev = decode_tail(old);
WRITE_ONCE(prev->next, node);
/*
* we're at the head of the waitqueue, wait for the owner & pending to
* go away.
*
* *,x,y -> *,0,0
*
* this wait loop must use a load-acquire such that we match the
* store-release that clears the locked bit and create lock
* sequentiality; this is because the set_locked() function below
* does not imply a full barrier.
*
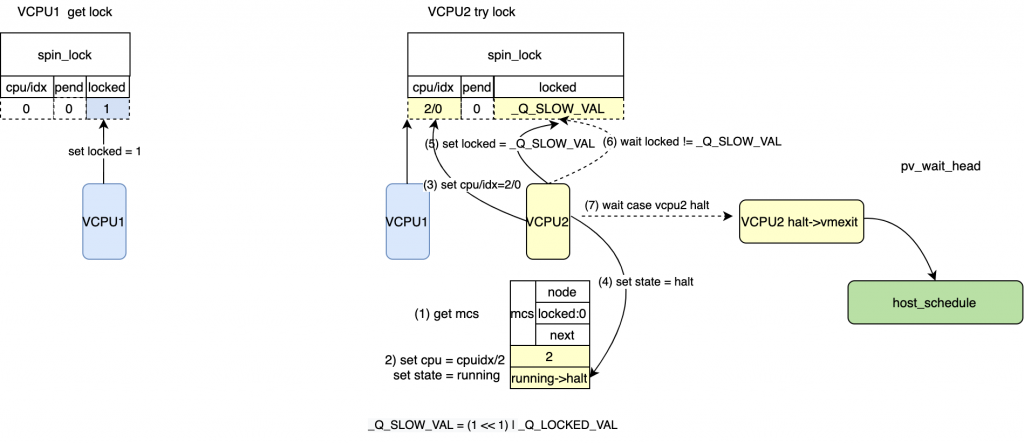
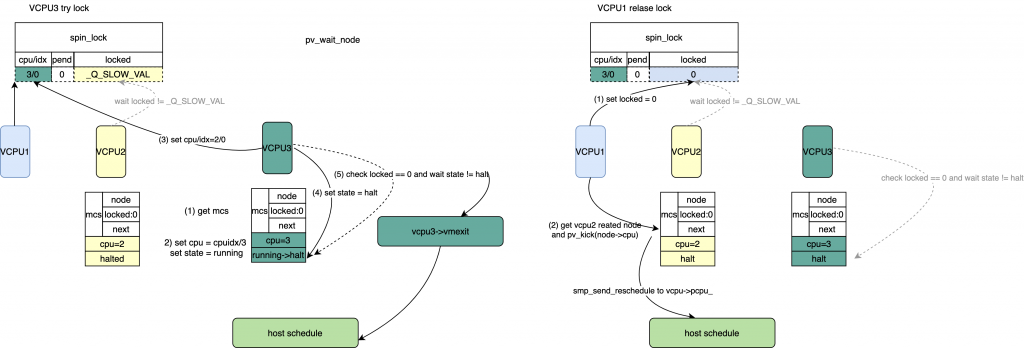
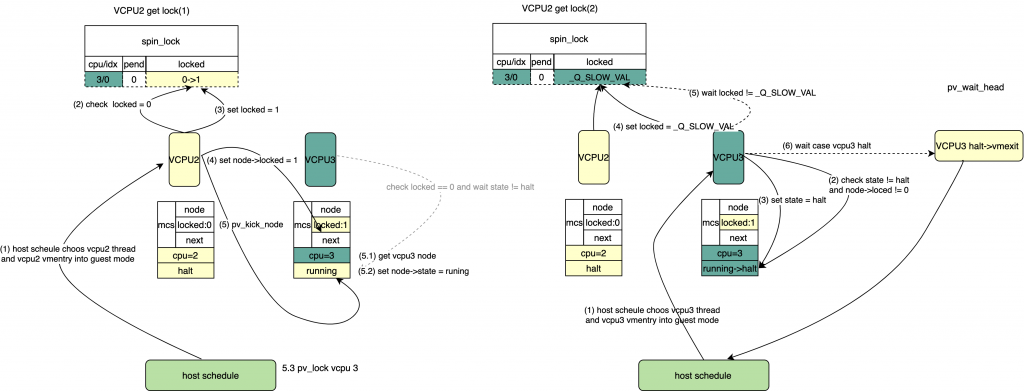
*/ /* pv: 设置locked = _Q_SLOW_VAL, 如果该锁还是没有释放,等待一些循环后,halt
* 然后vmexit到host, 该等待的node 会被hash, 在unlock的时候被获取到。
*/
pv_wait_head(lock, node); /* 等待locked && pend 都被clear */ while((val = smp_load_acquire(&lock->val.counter))& _Q_LOCKED_PENDING_MASK)
cpu_relax();
/*
* claim the lock:
*
* n,0,0 -> 0,0,1 : lock, uncontended
* *,0,0 -> *,0,1 : lock, contended
*
* If the queue head is the only one in the queue (lock value == tail),
* clear the tail code and grab the lock. Otherwise, we only need
* to grab the lock.
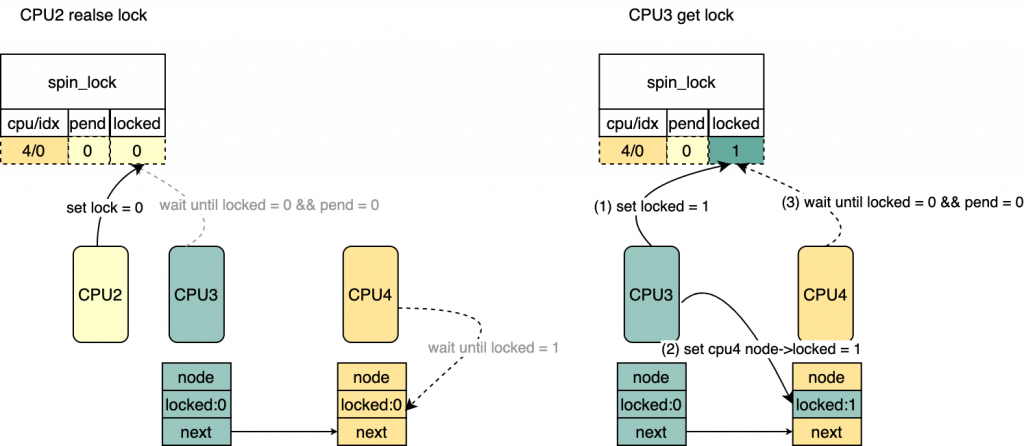
*/ for(;;){ /* 该CPU对应的mcs不是最后一个等待的lock的CPU, 直接set lock
* 注意这里并没有修改lock->tail(cpu/idx)以及pending
* 图中CPU3 get lock
*/ if(val != tail){
set_locked(lock); break; }
/* 该CPU是最后一个等待锁的CPU,直接修改
* lock->val = LOCKED_VAL,相当于clear 了tail/pending,
* 并且set了locked
* 对应图中 CPU4 get lock
*/
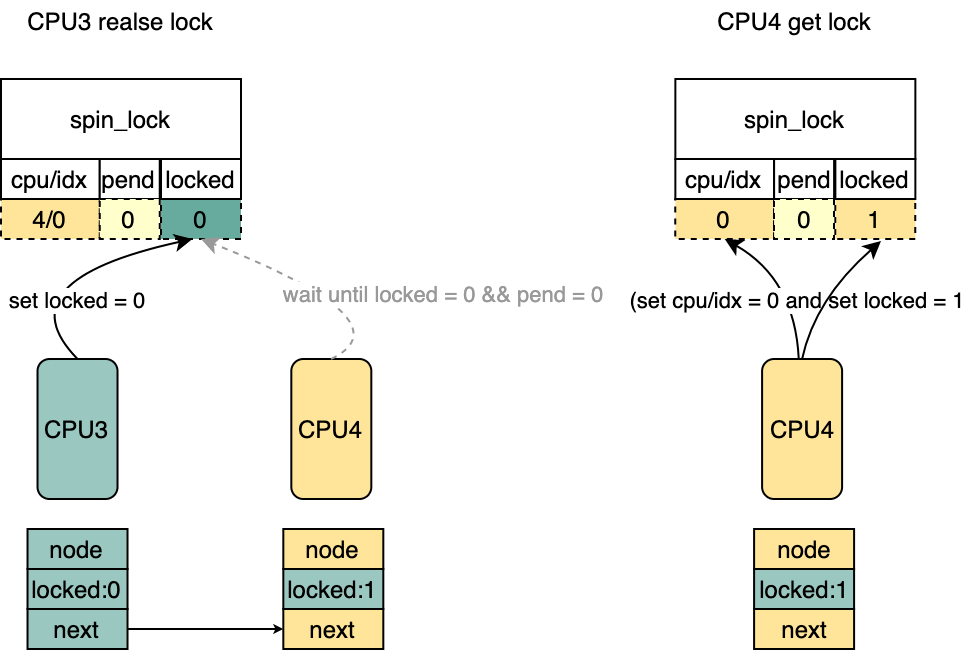
old = atomic_cmpxchg(&lock->val, val, _Q_LOCKED_VAL); if(old == val) goto release;/* No contention */
/*
* We must not unlock if SLOW, because in that case we must first
* unhash. Otherwise it would be possible to have multiple @lock
* entries, which would be BAD.
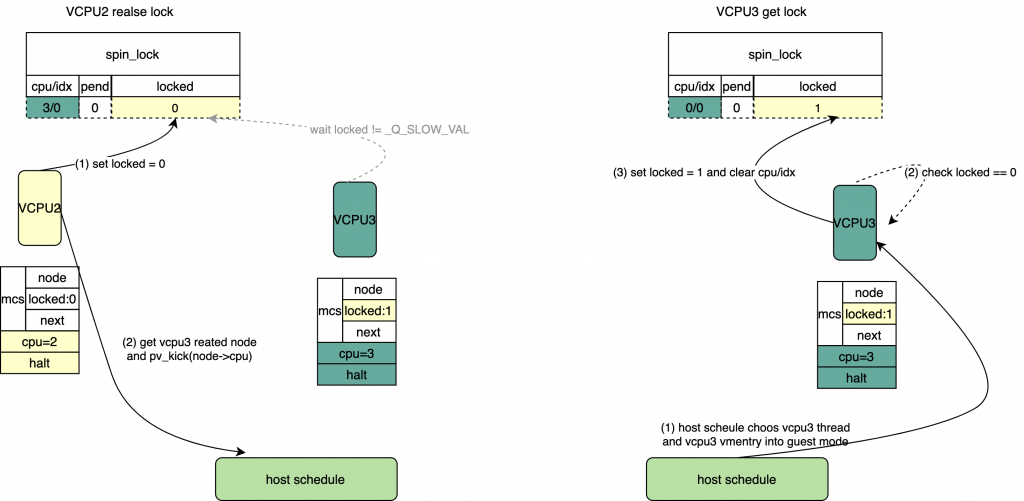
*/ if(likely(cmpxchg(&l->locked, _Q_LOCKED_VAL,0)== _Q_LOCKED_VAL)) return;
/*
* Since the above failed to release, this must be the SLOW path.
* Therefore start by looking up the blocked node and unhashing it.
*/ /*通过lock获得头部等待的vcpu 对应的pv_node */
node = pv_unhash(lock);
/*
* Now that we have a reference to the (likely) blocked pv_node,
* release the lock.
*/ /* set spinlock->lock = 0 */
smp_store_release(&l->locked,0);
/*
* At this point the memory pointed at by lock can be freed/reused,
* however we can still use the pv_node to kick the CPU.
*/ /* halt唤醒vcpu */ if(READ_ONCE(node->state)== vcpu_halted)
pv_kick(node->cpu); }