/*
* we won the trylock
*/ if(new == _Q_LOCKED_VAL) /* 这里代表上面的逻辑中,val被改为了0, 也就是锁被释放了 */ return;
/*
* we're pending, wait for the owner to go away.
*
* *,1,1 -> *,1,0
*
* this wait loop must be a load-acquire such that we match the
* store-release that clears the locked bit and create lock
* sequentiality; this is because not all clear_pending_set_locked()
* implementations imply full barriers.
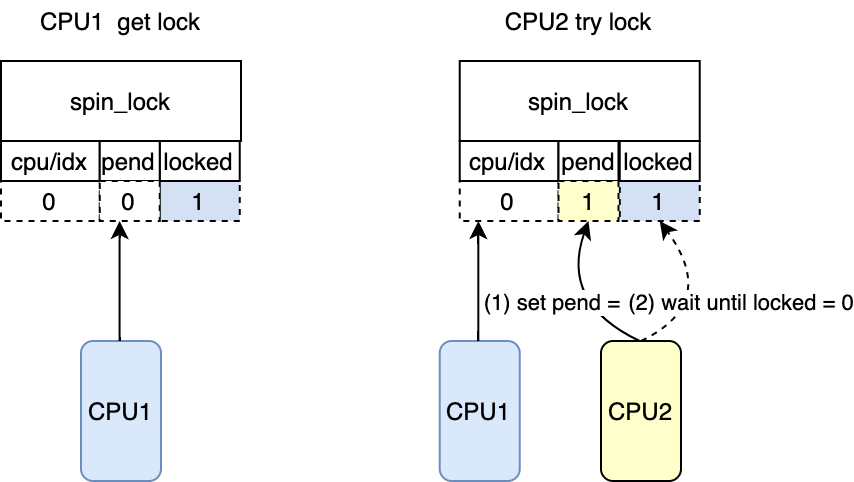
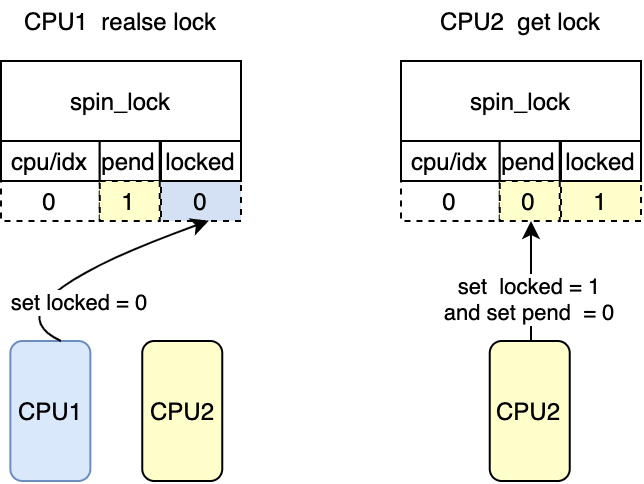
*/ while((val = smp_load_acquire(&lock->val.counter))& _Q_LOCKED_MASK) /* 等到该锁的被释放 对应图中CPU2 try lock*/
cpu_relax();
/*
* take ownership and clear the pending bit.
*
* *,1,0 -> *,0,1
*/ /* 获取该锁,对应图中CPU2 get lock */
clear_pending_set_locked(lock); return;
/*
* End of pending bit optimistic spinning and beginning of MCS
* queuing.
*/
queue: /* 获得该CPU上的空闲的mcs_lock 并初始化 */
node = this_cpu_ptr(&mcs_nodes[0]);
idx = node->count++;
tail = encode_tail(smp_processor_id(), idx);
/*
* We touched a (possibly) cold cacheline in the per-cpu queue node;
* attempt the trylock once more in the hope someone let go while we
* weren't watching.
*/ /* 优化 */ if(queued_spin_trylock(lock)) goto release;
/*
* We have already touched the queueing cacheline; don't bother with
* pending stuff.
*
* p,*,* -> n,*,*
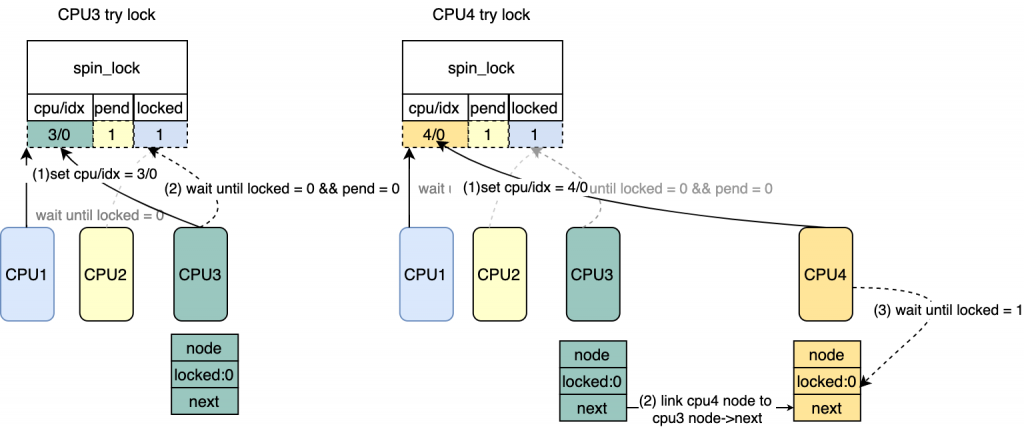
*/ /* 将tail 更新到lock tail(cpu/idx) 并且返回原来的tail
* 表示最后一个想要获得锁的CPU
* 图中CPU3 try lock的时候会写入,CPU4在try lock的时候
* 也会写入会覆盖CPU3写入的,来表示CPU4是最后一个想要
* 获得锁的。
*/
old = xchg_tail(lock, tail);
/*
* if there was a previous node; link it and wait until reaching the
* head of the waitqueue.
*/ /* 判断当前有没有多于2个CPU在等待锁,如果有把mcs链接到
* last mcs->next。
* 针对图中CPU3来说,old = 0, 说明只有一个等待锁
* 针对图中CPU4来说,old = CPU3/IDX, 需要把CPU4对应的mcs链接到CPU3/idx mcs->next
* 现在等待锁的是CPU2 CPU3。
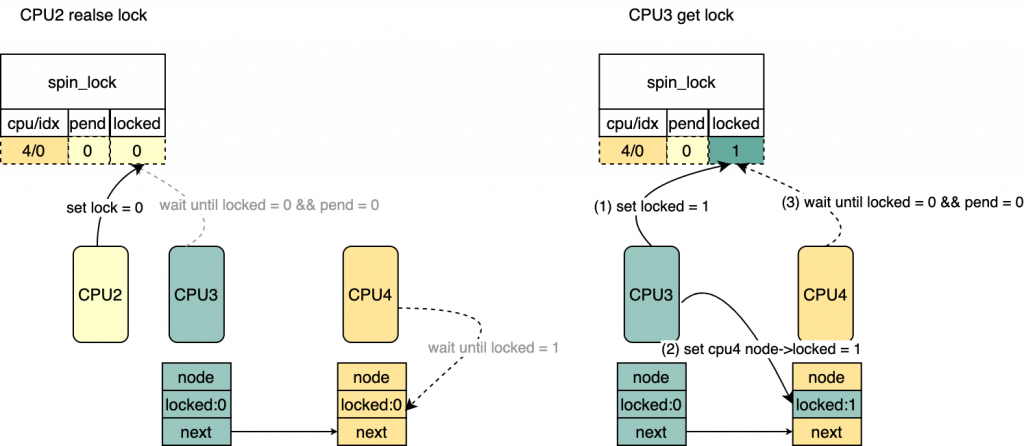
*/ if(old & _Q_TAIL_MASK){
prev = decode_tail(old);
WRITE_ONCE(prev->next, node);
/*
* we're at the head of the waitqueue, wait for the owner & pending to
* go away.
*
* *,x,y -> *,0,0
*
* this wait loop must use a load-acquire such that we match the
* store-release that clears the locked bit and create lock
* sequentiality; this is because the set_locked() function below
* does not imply a full barrier.
*
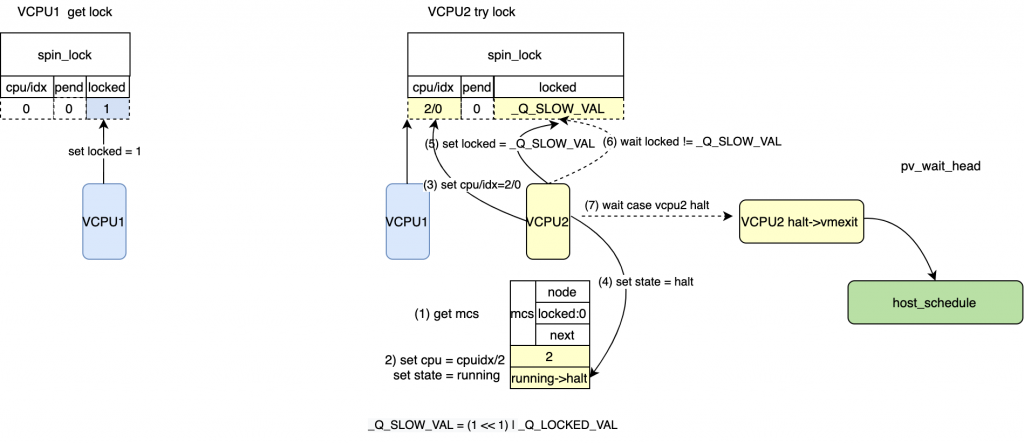
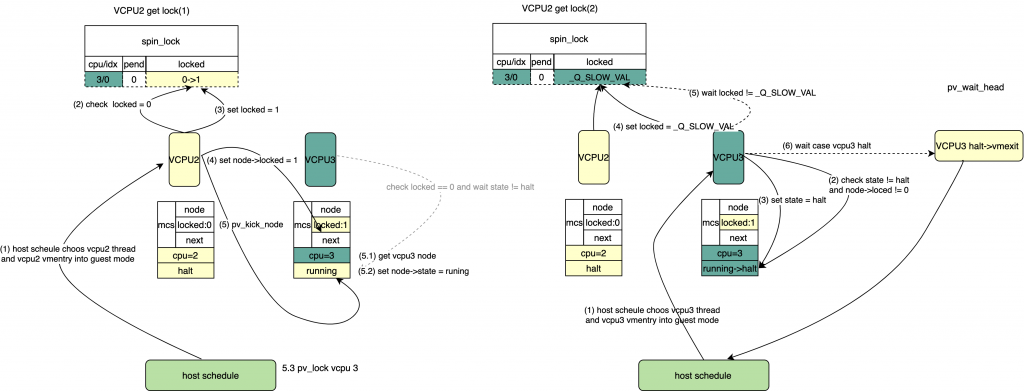
*/ /* pv: 设置locked = _Q_SLOW_VAL, 如果该锁还是没有释放,等待一些循环后,halt
* 然后vmexit到host, 该等待的node 会被hash, 在unlock的时候被获取到。
*/
pv_wait_head(lock, node); /* 等待locked && pend 都被clear */ while((val = smp_load_acquire(&lock->val.counter))& _Q_LOCKED_PENDING_MASK)
cpu_relax();
/*
* claim the lock:
*
* n,0,0 -> 0,0,1 : lock, uncontended
* *,0,0 -> *,0,1 : lock, contended
*
* If the queue head is the only one in the queue (lock value == tail),
* clear the tail code and grab the lock. Otherwise, we only need
* to grab the lock.
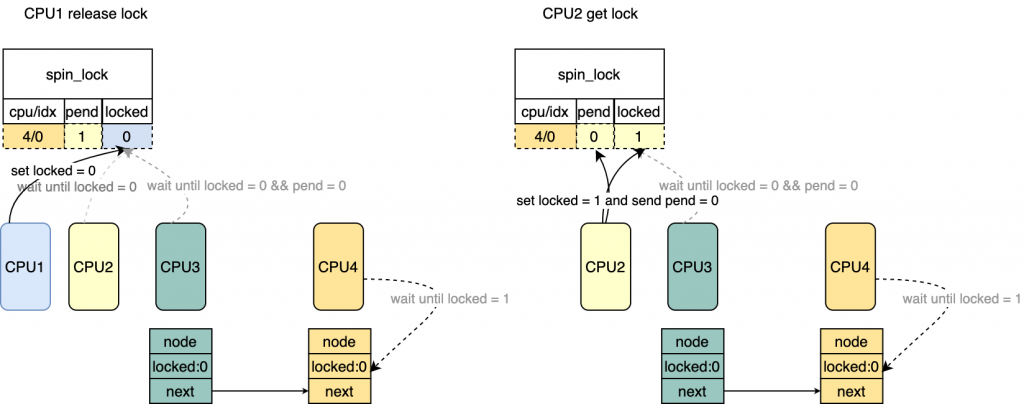
*/ for(;;){ /* 该CPU对应的mcs不是最后一个等待的lock的CPU, 直接set lock
* 注意这里并没有修改lock->tail(cpu/idx)以及pending
* 图中CPU3 get lock
*/ if(val != tail){
set_locked(lock); break; }
/* 该CPU是最后一个等待锁的CPU,直接修改
* lock->val = LOCKED_VAL,相当于clear 了tail/pending,
* 并且set了locked
* 对应图中 CPU4 get lock
*/
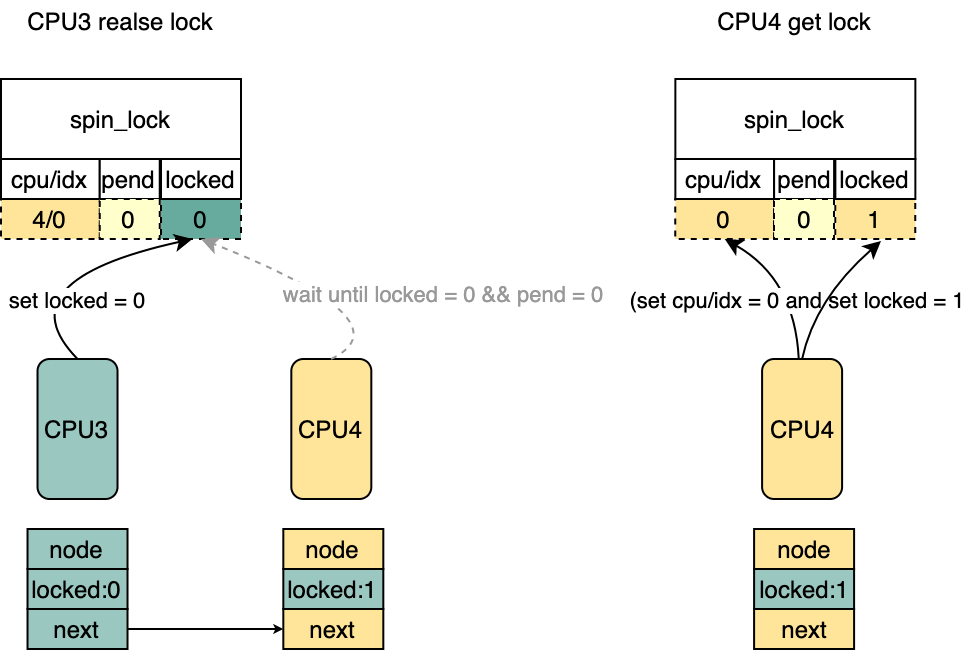
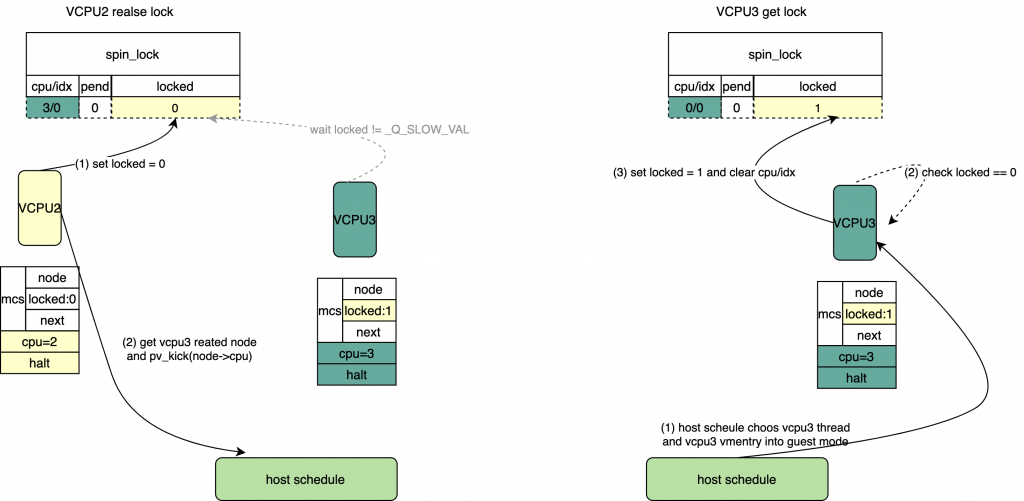
old = atomic_cmpxchg(&lock->val, val, _Q_LOCKED_VAL); if(old == val) goto release;/* No contention */
/*
* We must not unlock if SLOW, because in that case we must first
* unhash. Otherwise it would be possible to have multiple @lock
* entries, which would be BAD.
*/ if(likely(cmpxchg(&l->locked, _Q_LOCKED_VAL,0)== _Q_LOCKED_VAL)) return;
/*
* Since the above failed to release, this must be the SLOW path.
* Therefore start by looking up the blocked node and unhashing it.
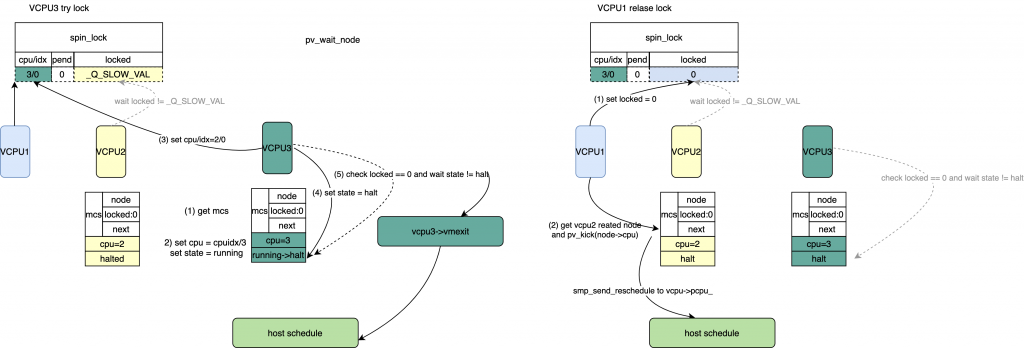
*/ /*通过lock获得头部等待的vcpu 对应的pv_node */
node = pv_unhash(lock);
/*
* Now that we have a reference to the (likely) blocked pv_node,
* release the lock.
*/ /* set spinlock->lock = 0 */
smp_store_release(&l->locked,0);
/*
* At this point the memory pointed at by lock can be freed/reused,
* however we can still use the pv_node to kick the CPU.
*/ /* halt唤醒vcpu */ if(READ_ONCE(node->state)== vcpu_halted)
pv_kick(node->cpu); }