mutex 和其他lock最大的区别是,拿着mutex是可以睡眠的,并且如果在尝试获得锁的情况下也是可以睡眠的。(分析基于base commit a33fda35e3a7655fb7df756ed67822afb5ed5e8d)。
1. structure
struct mutex {
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
atomic_t count;
spinlock_t wait_lock;
struct list_head wait_list;
#if defined(CONFIG_DEBUG_MUTEXES) || defined(CONFIG_MUTEX_SPIN_ON_OWNER)
struct task_struct *owner;
#endif
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
atomic_t count;
spinlock_t wait_lock;
struct list_head wait_list;
#if defined(CONFIG_DEBUG_MUTEXES) || defined(CONFIG_MUTEX_SPIN_ON_OWNER)
struct task_struct *owner;
#endif
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
2. 5个task 同时抢mutex的过程
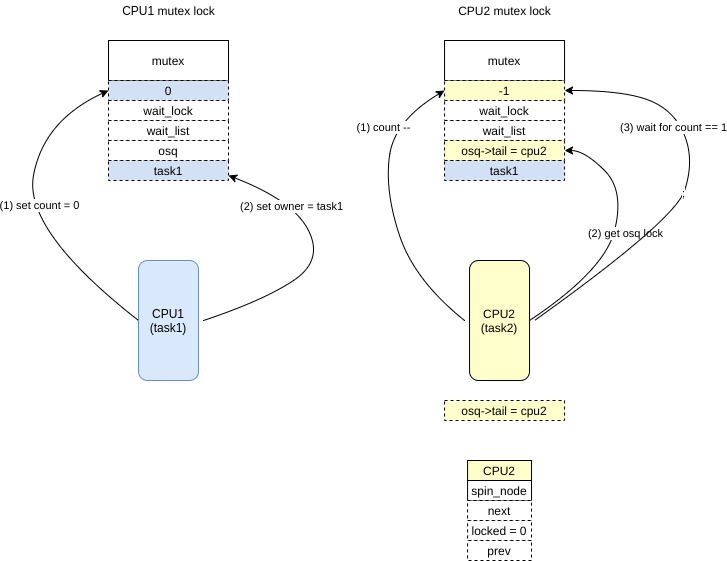
- CPU1 (task1) 想要获得该mutex,设置count = 0,设置owner = task1
- CPU2 (task2) 尝试获得该mutex,首先count –,发现count < 0,走到slow path,首先获取osq lock(这里假设当前task1->on_cpu是设置的,也就是task1可能会很快会释放锁)(这是一种类似qlock的mcs lock,主要区别在于osq lock,在spin 期间是如果发现自己可以发生调度的话,是可以dequeue自己,然后发生调度的),并且设置osq->tail = CPU2,然后CPU2 会等待count 变为 1
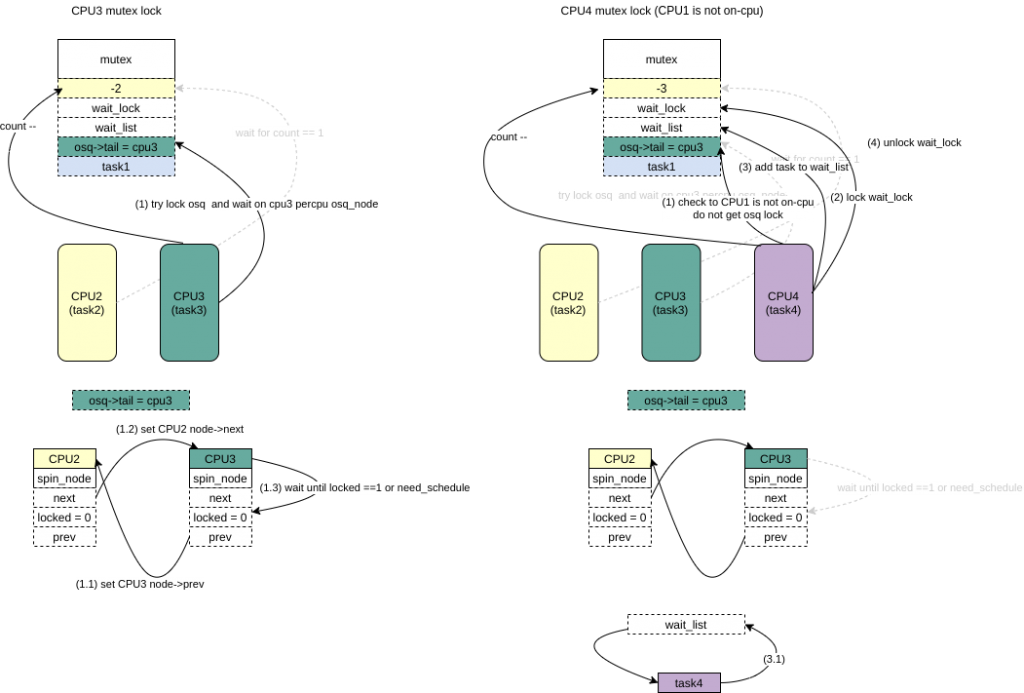
- CPU3 想要获取mutex,同样会对count — ,发现count < 0,走slowpath,首先会获取osq锁,该锁已经被CPU2(task2)获得,task3 获取CPU3上percpu的node,将自己写入osq->tail,然后将node链接到CPU2(task2)对应的node上,然后等待自己的node->lock 变为1或者need_schedule被设置。
- CPU4想要获取mutex,对count — ,发现count < 0,走slowpath,这里假设task1->on_cpu没有被设置,那么CPU4(task4)不在尝试获得osq 锁,而是将自己加入到mutex->wait_list上,设置为TASK_UNINTERRUPTIBLE,发生调度。
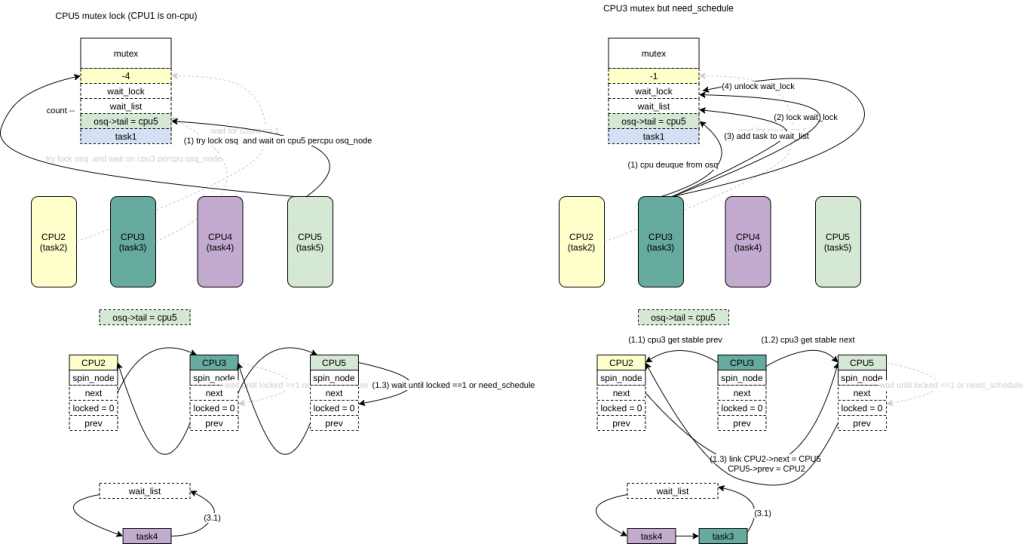
- CPU5(task5)想要获得该锁,count –,走slowpath,假设这个时候task1->on_cpu = 1被设置了也即是task1在CPU1上运行了,CPU5会尝试获取osq锁,该锁已经被CPU2(task2)获得,task5 获取CPU5上percpu的node,将自己写入osq->tail,然后将node链接到CPU3(task3)(prev_tail)对应的node上,然后等待自己的node3->lock 变为1或者need_schedule被设置。
- CPU3 need_schedule被设置了,CPU3会将自己的在osq的node list上面去掉,并且重新连接CPU2和CPU5(这个过程比较复杂,因为设计到node3->prev/next 必须是一个确定的值,因为CPU2/CPU5 本省也是可能会把自己在nodelist中剥离出去,后面的code有详细分析一个corner case,大体的实现通过atomic_xchg/cmpxchg的动作获得prev/next的同时设置为NULL),然后task3 会把自己加入到wait_list里面。
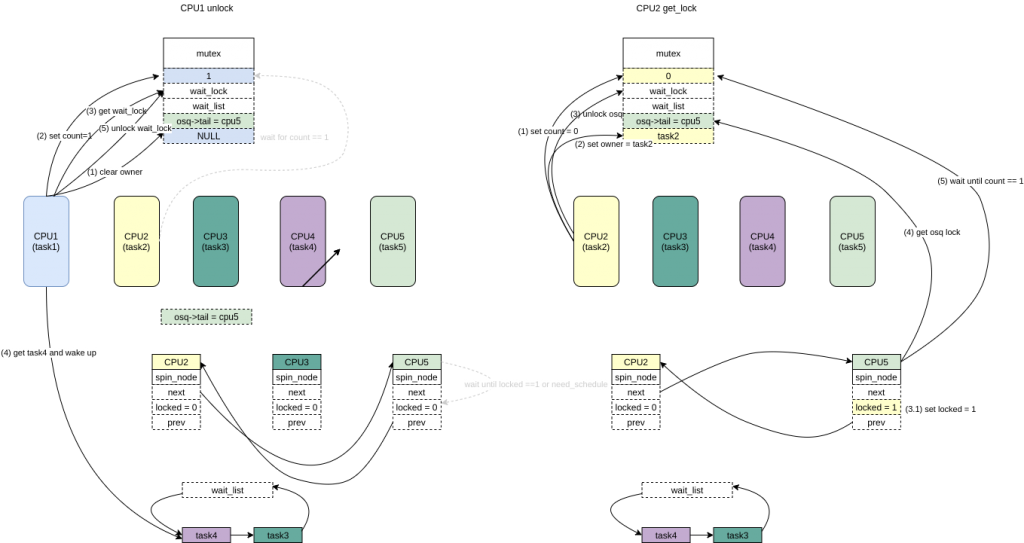
- CPU1(task1) unlock会将count 设置为0,并且会选择wait_list头部的任务进行wakeup(wait_lock保证wait_list的互斥)。这里大概率会是task2先获取到锁,但是也有可能task4获取到锁。
- CPU2看到了count = 1 后设置count = 0,设置owner = task2,unlock了osq,看到了CPU5(task5)在等待该osq lock,将该锁osq lock->locked设置为1,CPU5(task5)拿到了osq lock,等待count == 1。
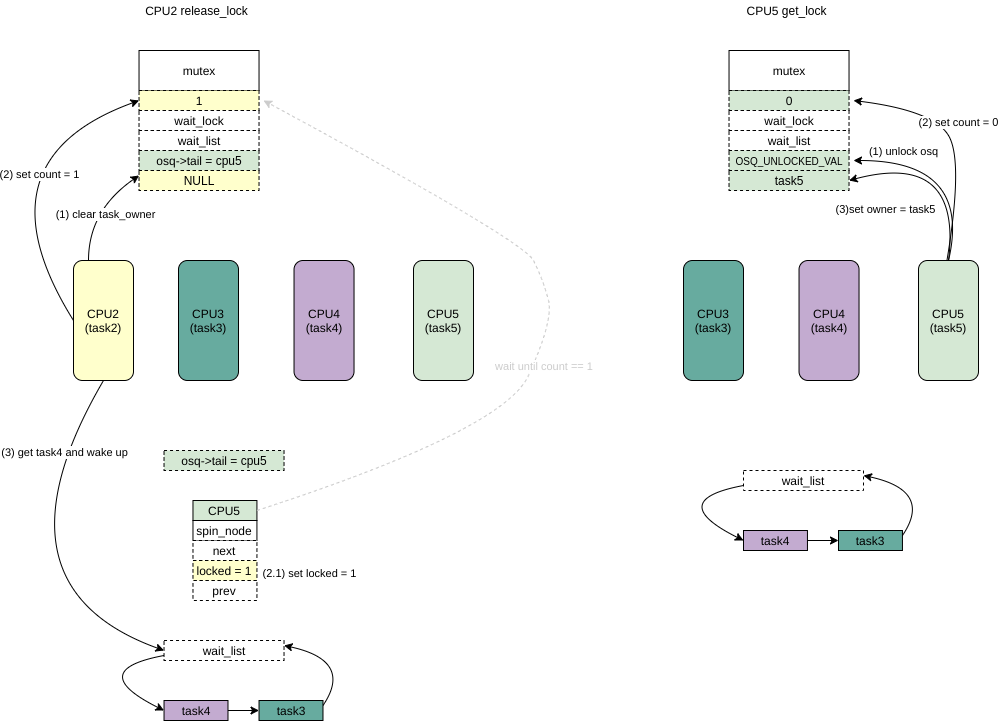
- CPU2 释放锁,清owner,设置 count = 1,选择wait_list的头部任务task4 然后 wakeup。
- CPU5拿到了mutex,首先是设置count = 0, 然后设置owner =task5,最后unlock osq锁。
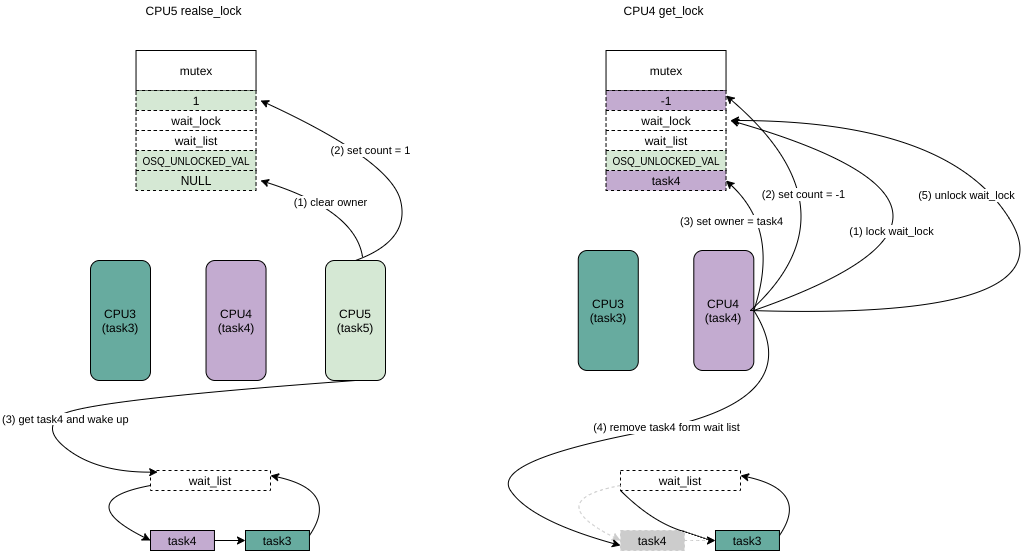
- CPU5(task5)释放锁,首先clear owner,然后设置 count =1, 然后选择wait_list中的任务wakeup。
- CPU4 被wakeup 后,拿wait_lock,修改任务状态为TASK_RUNNING,设置count = -1 (因为wait_list里面还有task3),然后设置owner = task4,将task4从wait_list去掉,最后释放wait_lock。
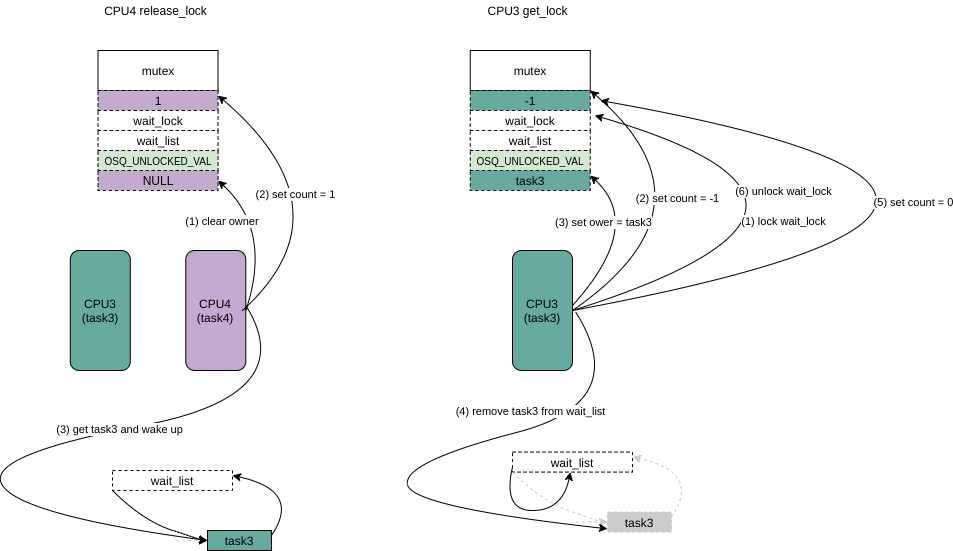
- CPU4(task4)释放锁,首先clear owner,然后set count =1,然后选择wait_list中的任务task3 wakeup。
- CPU3 被wakeup 后,拿wait_lock,设置count = -1,然后设置owner = task4,将task3从wait_list去掉,因为wait_list中已经没有等待的任务了,设置count = 0,最后释放wait_lock。
3. code
#define __mutex_fastpath_lock(v, fail_fn) \
do { \
unsigned long dummy; \
\
typecheck(atomic_t *, v); \
typecheck_fn(void (*)(atomic_t *), fail_fn); \
\
/* lock->count -- */
/* if lock->count < 0, call fail_fn */
asm volatile(LOCK_PREFIX " decl (%%rdi)\n" \
" jns 1f \n" \
" call " #fail_fn "\n" \
"1:" \
: "=D" (dummy) \
: "D" (v) \
: "rax", "rsi", "rdx", "rcx", \
"r8", "r9", "r10", "r11", "memory"); \
} while (0)
__visible void __sched
__mutex_lock_slowpath(atomic_t *lock_count)
{
struct mutex *lock = container_of(lock_count, struct mutex, count);
__mutex_lock_common(lock, TASK_UNINTERRUPTIBLE, 0,
NULL, _RET_IP_, NULL, 0);
}
do { \
unsigned long dummy; \
\
typecheck(atomic_t *, v); \
typecheck_fn(void (*)(atomic_t *), fail_fn); \
\
/* lock->count -- */
/* if lock->count < 0, call fail_fn */
asm volatile(LOCK_PREFIX " decl (%%rdi)\n" \
" jns 1f \n" \
" call " #fail_fn "\n" \
"1:" \
: "=D" (dummy) \
: "D" (v) \
: "rax", "rsi", "rdx", "rcx", \
"r8", "r9", "r10", "r11", "memory"); \
} while (0)
__visible void __sched
__mutex_lock_slowpath(atomic_t *lock_count)
{
struct mutex *lock = container_of(lock_count, struct mutex, count);
__mutex_lock_common(lock, TASK_UNINTERRUPTIBLE, 0,
NULL, _RET_IP_, NULL, 0);
}
*
* Lock a mutex (possibly interruptible), slowpath:
*/
static __always_inline int __sched
__mutex_lock_common(struct mutex *lock, long state, unsigned int subclass,
struct lockdep_map *nest_lock, unsigned long ip,
struct ww_acquire_ctx *ww_ctx, const bool use_ww_ctx)
{
struct task_struct *task = current;
struct mutex_waiter waiter;
unsigned long flags;
int ret;
preempt_disable();
mutex_acquire_nest(&lock->dep_map, subclass, 0, nest_lock, ip);
/* 1. 通过mcs_lock带来的短暂的spin动作获得该mutex */
if (mutex_optimistic_spin(lock, ww_ctx, use_ww_ctx)) {
/* got the lock, yay! */
preempt_enable();
return 0;
}
/* 2. wait_lock 是为了让所有cpu 线性的去访问锁并且保护wait_list */
spin_lock_mutex(&lock->wait_lock, flags);
/*
* Once more, try to acquire the lock. Only try-lock the mutex if
* it is unlocked to reduce unnecessary xchg() operations.
*/
if (!mutex_is_locked(lock) && (atomic_xchg(&lock->count, 0) == 1))
goto skip_wait;
debug_mutex_lock_common(lock, &waiter);
debug_mutex_add_waiter(lock, &waiter, task_thread_info(task));
/* add waiting tasks to the end of the waitqueue (FIFO): */
/* 加入到waiter list中 */
list_add_tail(&waiter.list, &lock->wait_list);
waiter.task = task;
lock_contended(&lock->dep_map, ip);
for (;;) {
/*
* Lets try to take the lock again - this is needed even if
* we get here for the first time (shortly after failing to
* acquire the lock), to make sure that we get a wakeup once
* it's unlocked. Later on, if we sleep, this is the
* operation that gives us the lock. We xchg it to -1, so
* that when we release the lock, we properly wake up the
* other waiters. We only attempt the xchg if the count is
* non-negative in order to avoid unnecessary xchg operations:
*/
if (atomic_read(&lock->count) >= 0 &&
(atomic_xchg(&lock->count, -1) == 1))
break;
/*
* got a signal? (This code gets eliminated in the
* TASK_UNINTERRUPTIBLE case.)
*/
if (unlikely(signal_pending_state(state, task))) {
ret = -EINTR;
goto err;
}
if (use_ww_ctx && ww_ctx->acquired > 0) {
ret = __ww_mutex_lock_check_stamp(lock, ww_ctx);
if (ret)
goto err;
}
__set_task_state(task, state);
/* didn't get the lock, go to sleep: */
spin_unlock_mutex(&lock->wait_lock, flags);
/* 主动调度 */
schedule_preempt_disabled();
spin_lock_mutex(&lock->wait_lock, flags);
}
/* 到这里说明获得了该锁 */
__set_task_state(task, TASK_RUNNING);
mutex_remove_waiter(lock, &waiter, current_thread_info());
/* set it to 0 if there are no waiters left: */
if (likely(list_empty(&lock->wait_list)))
/* 这里因为前面的会把lock->count 直接写入为 -1, 所以如果没有其他在wait_list的人直接设置为 0 */
atomic_set(&lock->count, 0);
debug_mutex_free_waiter(&waiter);
skip_wait:
/* got the lock - cleanup and rejoice! */
lock_acquired(&lock->dep_map, ip);
mutex_set_owner(lock);
if (use_ww_ctx) {
struct ww_mutex *ww = container_of(lock, struct ww_mutex, base);
ww_mutex_set_context_slowpath(ww, ww_ctx);
}
spin_unlock_mutex(&lock->wait_lock, flags);
preempt_enable();
return 0;
err:
mutex_remove_waiter(lock, &waiter, task_thread_info(task));
spin_unlock_mutex(&lock->wait_lock, flags);
debug_mutex_free_waiter(&waiter);
mutex_release(&lock->dep_map, 1, ip);
preempt_enable();
return ret;
}
* Lock a mutex (possibly interruptible), slowpath:
*/
static __always_inline int __sched
__mutex_lock_common(struct mutex *lock, long state, unsigned int subclass,
struct lockdep_map *nest_lock, unsigned long ip,
struct ww_acquire_ctx *ww_ctx, const bool use_ww_ctx)
{
struct task_struct *task = current;
struct mutex_waiter waiter;
unsigned long flags;
int ret;
preempt_disable();
mutex_acquire_nest(&lock->dep_map, subclass, 0, nest_lock, ip);
/* 1. 通过mcs_lock带来的短暂的spin动作获得该mutex */
if (mutex_optimistic_spin(lock, ww_ctx, use_ww_ctx)) {
/* got the lock, yay! */
preempt_enable();
return 0;
}
/* 2. wait_lock 是为了让所有cpu 线性的去访问锁并且保护wait_list */
spin_lock_mutex(&lock->wait_lock, flags);
/*
* Once more, try to acquire the lock. Only try-lock the mutex if
* it is unlocked to reduce unnecessary xchg() operations.
*/
if (!mutex_is_locked(lock) && (atomic_xchg(&lock->count, 0) == 1))
goto skip_wait;
debug_mutex_lock_common(lock, &waiter);
debug_mutex_add_waiter(lock, &waiter, task_thread_info(task));
/* add waiting tasks to the end of the waitqueue (FIFO): */
/* 加入到waiter list中 */
list_add_tail(&waiter.list, &lock->wait_list);
waiter.task = task;
lock_contended(&lock->dep_map, ip);
for (;;) {
/*
* Lets try to take the lock again - this is needed even if
* we get here for the first time (shortly after failing to
* acquire the lock), to make sure that we get a wakeup once
* it's unlocked. Later on, if we sleep, this is the
* operation that gives us the lock. We xchg it to -1, so
* that when we release the lock, we properly wake up the
* other waiters. We only attempt the xchg if the count is
* non-negative in order to avoid unnecessary xchg operations:
*/
if (atomic_read(&lock->count) >= 0 &&
(atomic_xchg(&lock->count, -1) == 1))
break;
/*
* got a signal? (This code gets eliminated in the
* TASK_UNINTERRUPTIBLE case.)
*/
if (unlikely(signal_pending_state(state, task))) {
ret = -EINTR;
goto err;
}
if (use_ww_ctx && ww_ctx->acquired > 0) {
ret = __ww_mutex_lock_check_stamp(lock, ww_ctx);
if (ret)
goto err;
}
__set_task_state(task, state);
/* didn't get the lock, go to sleep: */
spin_unlock_mutex(&lock->wait_lock, flags);
/* 主动调度 */
schedule_preempt_disabled();
spin_lock_mutex(&lock->wait_lock, flags);
}
/* 到这里说明获得了该锁 */
__set_task_state(task, TASK_RUNNING);
mutex_remove_waiter(lock, &waiter, current_thread_info());
/* set it to 0 if there are no waiters left: */
if (likely(list_empty(&lock->wait_list)))
/* 这里因为前面的会把lock->count 直接写入为 -1, 所以如果没有其他在wait_list的人直接设置为 0 */
atomic_set(&lock->count, 0);
debug_mutex_free_waiter(&waiter);
skip_wait:
/* got the lock - cleanup and rejoice! */
lock_acquired(&lock->dep_map, ip);
mutex_set_owner(lock);
if (use_ww_ctx) {
struct ww_mutex *ww = container_of(lock, struct ww_mutex, base);
ww_mutex_set_context_slowpath(ww, ww_ctx);
}
spin_unlock_mutex(&lock->wait_lock, flags);
preempt_enable();
return 0;
err:
mutex_remove_waiter(lock, &waiter, task_thread_info(task));
spin_unlock_mutex(&lock->wait_lock, flags);
debug_mutex_free_waiter(&waiter);
mutex_release(&lock->dep_map, 1, ip);
preempt_enable();
return ret;
}
mutex_optimistic_spin主要是为了更快速的拿mutex,而不是先wait然後睡眠.
/*
* Optimistic spinning.
*
* We try to spin for acquisition when we find that the lock owner
* is currently running on a (different) CPU and while we don't
* need to reschedule. The rationale is that if the lock owner is
* running, it is likely to release the lock soon.
*
* Since this needs the lock owner, and this mutex implementation
* doesn't track the owner atomically in the lock field, we need to
* track it non-atomically.
*
* We can't do this for DEBUG_MUTEXES because that relies on wait_lock
* to serialize everything.
*
* The mutex spinners are queued up using MCS lock so that only one
* spinner can compete for the mutex. However, if mutex spinning isn't
* going to happen, there is no point in going through the lock/unlock
* overhead.
*
* Returns true when the lock was taken, otherwise false, indicating
* that we need to jump to the slowpath and sleep.
*/
static bool mutex_optimistic_spin(struct mutex *lock,
struct ww_acquire_ctx *ww_ctx, const bool use_ww_ctx)
{
struct task_struct *task = current;
/* 检查获得锁的task是否on_cpu也就是在运行中, on_cpu会在context_switch时候设置 */
if (!mutex_can_spin_on_owner(lock))
goto done;
/*
* In order to avoid a stampede of mutex spinners trying to
* acquire the mutex all at once, the spinners need to take a
* MCS (queued) lock first before spinning on the owner field.
*/
if (!osq_lock(&lock->osq))
goto done;
while (true) {
struct task_struct *owner;
if (use_ww_ctx && ww_ctx->acquired > 0) {
struct ww_mutex *ww;
ww = container_of(lock, struct ww_mutex, base);
/*
* If ww->ctx is set the contents are undefined, only
* by acquiring wait_lock there is a guarantee that
* they are not invalid when reading.
*
* As such, when deadlock detection needs to be
* performed the optimistic spinning cannot be done.
*/
if (READ_ONCE(ww->ctx))
break;
}
/*
* If there's an owner, wait for it to either
* release the lock or go to sleep.
*/
owner = READ_ONCE(lock->owner);
if (owner && !mutex_spin_on_owner(lock, owner))
break;
/* Try to acquire the mutex if it is unlocked. */
if (mutex_try_to_acquire(lock)) {
lock_acquired(&lock->dep_map, ip);
if (use_ww_ctx) {
struct ww_mutex *ww;
ww = container_of(lock, struct ww_mutex, base);
ww_mutex_set_context_fastpath(ww, ww_ctx);
}
mutex_set_owner(lock);
osq_unlock(&lock->osq);
return true;
}
/*
* When there's no owner, we might have preempted between the
* owner acquiring the lock and setting the owner field. If
* we're an RT task that will live-lock because we won't let
* the owner complete.
*/
if (!owner && (need_resched() || rt_task(task)))
break;
/*
* The cpu_relax() call is a compiler barrier which forces
* everything in this loop to be re-loaded. We don't need
* memory barriers as we'll eventually observe the right
* values at the cost of a few extra spins.
*/
cpu_relax_lowlatency();
}
osq_unlock(&lock->osq);
done:
/*
* If we fell out of the spin path because of need_resched(),
* reschedule now, before we try-lock the mutex. This avoids getting
* scheduled out right after we obtained the mutex.
*/
if (need_resched()) {
/*
* We _should_ have TASK_RUNNING here, but just in case
* we do not, make it so, otherwise we might get stuck.
*/
__set_current_state(TASK_RUNNING);
schedule_preempt_disabled();
}
return false;
}
* Optimistic spinning.
*
* We try to spin for acquisition when we find that the lock owner
* is currently running on a (different) CPU and while we don't
* need to reschedule. The rationale is that if the lock owner is
* running, it is likely to release the lock soon.
*
* Since this needs the lock owner, and this mutex implementation
* doesn't track the owner atomically in the lock field, we need to
* track it non-atomically.
*
* We can't do this for DEBUG_MUTEXES because that relies on wait_lock
* to serialize everything.
*
* The mutex spinners are queued up using MCS lock so that only one
* spinner can compete for the mutex. However, if mutex spinning isn't
* going to happen, there is no point in going through the lock/unlock
* overhead.
*
* Returns true when the lock was taken, otherwise false, indicating
* that we need to jump to the slowpath and sleep.
*/
static bool mutex_optimistic_spin(struct mutex *lock,
struct ww_acquire_ctx *ww_ctx, const bool use_ww_ctx)
{
struct task_struct *task = current;
/* 检查获得锁的task是否on_cpu也就是在运行中, on_cpu会在context_switch时候设置 */
if (!mutex_can_spin_on_owner(lock))
goto done;
/*
* In order to avoid a stampede of mutex spinners trying to
* acquire the mutex all at once, the spinners need to take a
* MCS (queued) lock first before spinning on the owner field.
*/
if (!osq_lock(&lock->osq))
goto done;
while (true) {
struct task_struct *owner;
if (use_ww_ctx && ww_ctx->acquired > 0) {
struct ww_mutex *ww;
ww = container_of(lock, struct ww_mutex, base);
/*
* If ww->ctx is set the contents are undefined, only
* by acquiring wait_lock there is a guarantee that
* they are not invalid when reading.
*
* As such, when deadlock detection needs to be
* performed the optimistic spinning cannot be done.
*/
if (READ_ONCE(ww->ctx))
break;
}
/*
* If there's an owner, wait for it to either
* release the lock or go to sleep.
*/
owner = READ_ONCE(lock->owner);
if (owner && !mutex_spin_on_owner(lock, owner))
break;
/* Try to acquire the mutex if it is unlocked. */
if (mutex_try_to_acquire(lock)) {
lock_acquired(&lock->dep_map, ip);
if (use_ww_ctx) {
struct ww_mutex *ww;
ww = container_of(lock, struct ww_mutex, base);
ww_mutex_set_context_fastpath(ww, ww_ctx);
}
mutex_set_owner(lock);
osq_unlock(&lock->osq);
return true;
}
/*
* When there's no owner, we might have preempted between the
* owner acquiring the lock and setting the owner field. If
* we're an RT task that will live-lock because we won't let
* the owner complete.
*/
if (!owner && (need_resched() || rt_task(task)))
break;
/*
* The cpu_relax() call is a compiler barrier which forces
* everything in this loop to be re-loaded. We don't need
* memory barriers as we'll eventually observe the right
* values at the cost of a few extra spins.
*/
cpu_relax_lowlatency();
}
osq_unlock(&lock->osq);
done:
/*
* If we fell out of the spin path because of need_resched(),
* reschedule now, before we try-lock the mutex. This avoids getting
* scheduled out right after we obtained the mutex.
*/
if (need_resched()) {
/*
* We _should_ have TASK_RUNNING here, but just in case
* we do not, make it so, otherwise we might get stuck.
*/
__set_current_state(TASK_RUNNING);
schedule_preempt_disabled();
}
return false;
}
osq_lock/unlock逻辑如下,尤其代码中的osq_wait_next stablize next/prev的动作,代码中有个例子比较有趣.
bool osq_lock(struct optimistic_spin_queue *lock)
{
struct optimistic_spin_node *node = this_cpu_ptr(&osq_node);
struct optimistic_spin_node *prev, *next;
int curr = encode_cpu(smp_processor_id());
int old;
node->locked = 0;
node->next = NULL;
node->cpu = curr;
/* 设置 curr 到tail 代表的是当前最后等待lock的cpu */
old = atomic_xchg(&lock->tail, curr);
if (old == OSQ_UNLOCKED_VAL)
return true;
prev = decode_cpu(old);
node->prev = prev;
WRITE_ONCE(prev->next, node);
/*
* Normally @prev is untouchable after the above store; because at that
* moment unlock can proceed and wipe the node element from stack.
*
* However, since our nodes are static per-cpu storage, we're
* guaranteed their existence -- this allows us to apply
* cmpxchg in an attempt to undo our queueing.
*/
/* 等待自己的locked 被设置 */
while (!READ_ONCE(node->locked)) {
/*
* If we need to reschedule bail... so we can block.
*/
/* 这里是和qspinlock的区别,这里可能会调度出去 */
if (need_resched())
goto unqueue;
cpu_relax_lowlatency();
}
return true;
unqueue:
/*
* Step - A -- stabilize @prev
*
* Undo our @prev->next assignment; this will make @prev's
* unlock()/unqueue() wait for a next pointer since @lock points to us
* (or later).
*/
/*
* 这里是确定prev 到底的值,确定的方法是cmpxchg通过比较prev->next和
* node的值,如果prev->next==node, 设置prev->next = NULL, 以为上面的两个
* 动作是atomic的,prev->next = NULL后,代表的是prev->next是unstabled,
* 也就是说如果这种情况下 prev 有可能因为need_schedule的原因也要发生unqueue
* 动作,那么prev 在后面的stable next的时候会发现prev->next ==NULL, 所以
* 会一直等待.
* 例子假设当前的mcs_lock的链是:
* Begin:
* CPU1 ----> CPU2 ----> CPU3 ----> CPU4 CPU5
* hold_mutex ...... ...... ...... ......
* osq_get_lock ...... ...... ......
* osq_try_lock ...... ......
* ...... ...... ......
* ...... osq_try_lock ......
* wait(node3->locked) ...... ......
* ...... ...... osq_try_lock
* ...... wait(node4->locked) ......
* ...... ...... ......
* ...... ...... wait(node5->locked)
* need_sched() ...... ......
* unqueue
* ...... ...... ......
* ...... need_sched() ......
* ...... unqueue ......
* ...... ...... ......
* ...... ...... ......
* get_stable_prev(CPU2) ...... ......
* prev = CPU2
* CPU2->next = NULL
* ...... ...... ......
* ...... get_statble_prev(CPU3) ......
* prev = CPU3
* CPU3->next = NULL
* ...... ......
* ...... ......
* try_get_stable_next ......
* while(CPU3->next==NULL)
* loop
* ...... ......
* ...... ......
* ...... ......
* ...... get_stable_next
* next = CPU4->next(CPU5)
* CPU4->next = NULL
* ...... ......
* ...... ......
* ...... ......
* ...... ......
* prev(CPU3)->next = next(CPU5)
* prev(CPU5)->prev = prev(CPU3)
* ...... ......
* ...... ......
* loop end ......
* CPU3->next= CPU5
* next is stable
* ...... ......
* get_stable_next ......
* next = CPU5
* CPU3->next = NULL
* ...... ......
*
* prev(CPU2)->next = next(CPU5)
* prev(CPU5)->prev = prev(CPU2)
*
* End:
* CPU1 ----> CPU2 ----> CPU5
*/
for (;;) {
if (prev->next == node &&
cmpxchg(&prev->next, node, NULL) == node)
break;
/*
* We can only fail the cmpxchg() racing against an unlock(),
* in which case we should observe @node->locked becomming
* true.
*/
if (smp_load_acquire(&node->locked))
return true;
cpu_relax_lowlatency();
/*
* Or we race against a concurrent unqueue()'s step-B, in which
* case its step-C will write us a new @node->prev pointer.
*/
prev = READ_ONCE(node->prev);
}
/*
* Step - B -- stabilize @next
*
* Similar to unlock(), wait for @node->next or move @lock from @node
* back to @prev.
*/
next = osq_wait_next(lock, node, prev);
if (!next)
return false;
/*
* Step - C -- unlink
*
* @prev is stable because its still waiting for a new @prev->next
* pointer, @next is stable because our @node->next pointer is NULL and
* it will wait in Step-A.
*/
WRITE_ONCE(next->prev, prev);
WRITE_ONCE(prev->next, next);
return false;
}
void osq_unlock(struct optimistic_spin_queue *lock)
{
struct optimistic_spin_node *node, *next;
int curr = encode_cpu(smp_processor_id());
/*
* Fast path for the uncontended case.
*/
if (likely(atomic_cmpxchg(&lock->tail, curr, OSQ_UNLOCKED_VAL) == curr))
return;
/*
* Second most likely case.
*/
node = this_cpu_ptr(&osq_node);
next = xchg(&node->next, NULL);
if (next) {
WRITE_ONCE(next->locked, 1);
return;
}
/* 等待next 变成stable */
next = osq_wait_next(lock, node, NULL);
if (next)
/* 通知下一个等待的为 1 */
WRITE_ONCE(next->locked, 1);
}
/*
* Get a stable @node->next pointer, either for unlock() or unqueue() purposes.
* Can return NULL in case we were the last queued and we updated @lock instead.
*/
static inline struct optimistic_spin_node *
osq_wait_next(struct optimistic_spin_queue *lock,
struct optimistic_spin_node *node,
struct optimistic_spin_node *prev)
{
struct optimistic_spin_node *next = NULL;
int curr = encode_cpu(smp_processor_id());
int old;
/*
* If there is a prev node in queue, then the 'old' value will be
* the prev node's CPU #, else it's set to OSQ_UNLOCKED_VAL since if
* we're currently last in queue, then the queue will then become empty.
*/
old = prev ? prev->cpu : OSQ_UNLOCKED_VAL;
for (;;) {
if (atomic_read(&lock->tail) == curr &&
atomic_cmpxchg(&lock->tail, curr, old) == curr) {
/*
* We were the last queued, we moved @lock back. @prev
* will now observe @lock and will complete its
* unlock()/unqueue().
*/
break;
}
/*
* We must xchg() the @node->next value, because if we were to
* leave it in, a concurrent unlock()/unqueue() from
* @node->next might complete Step-A and think its @prev is
* still valid.
*
* If the concurrent unlock()/unqueue() wins the race, we'll
* wait for either @lock to point to us, through its Step-B, or
* wait for a new @node->next from its Step-C.
*/
if (node->next) {
next = xchg(&node->next, NULL);
if (next)
break;
}
cpu_relax_lowlatency();
}
return next;
}
{
struct optimistic_spin_node *node = this_cpu_ptr(&osq_node);
struct optimistic_spin_node *prev, *next;
int curr = encode_cpu(smp_processor_id());
int old;
node->locked = 0;
node->next = NULL;
node->cpu = curr;
/* 设置 curr 到tail 代表的是当前最后等待lock的cpu */
old = atomic_xchg(&lock->tail, curr);
if (old == OSQ_UNLOCKED_VAL)
return true;
prev = decode_cpu(old);
node->prev = prev;
WRITE_ONCE(prev->next, node);
/*
* Normally @prev is untouchable after the above store; because at that
* moment unlock can proceed and wipe the node element from stack.
*
* However, since our nodes are static per-cpu storage, we're
* guaranteed their existence -- this allows us to apply
* cmpxchg in an attempt to undo our queueing.
*/
/* 等待自己的locked 被设置 */
while (!READ_ONCE(node->locked)) {
/*
* If we need to reschedule bail... so we can block.
*/
/* 这里是和qspinlock的区别,这里可能会调度出去 */
if (need_resched())
goto unqueue;
cpu_relax_lowlatency();
}
return true;
unqueue:
/*
* Step - A -- stabilize @prev
*
* Undo our @prev->next assignment; this will make @prev's
* unlock()/unqueue() wait for a next pointer since @lock points to us
* (or later).
*/
/*
* 这里是确定prev 到底的值,确定的方法是cmpxchg通过比较prev->next和
* node的值,如果prev->next==node, 设置prev->next = NULL, 以为上面的两个
* 动作是atomic的,prev->next = NULL后,代表的是prev->next是unstabled,
* 也就是说如果这种情况下 prev 有可能因为need_schedule的原因也要发生unqueue
* 动作,那么prev 在后面的stable next的时候会发现prev->next ==NULL, 所以
* 会一直等待.
* 例子假设当前的mcs_lock的链是:
* Begin:
* CPU1 ----> CPU2 ----> CPU3 ----> CPU4 CPU5
* hold_mutex ...... ...... ...... ......
* osq_get_lock ...... ...... ......
* osq_try_lock ...... ......
* ...... ...... ......
* ...... osq_try_lock ......
* wait(node3->locked) ...... ......
* ...... ...... osq_try_lock
* ...... wait(node4->locked) ......
* ...... ...... ......
* ...... ...... wait(node5->locked)
* need_sched() ...... ......
* unqueue
* ...... ...... ......
* ...... need_sched() ......
* ...... unqueue ......
* ...... ...... ......
* ...... ...... ......
* get_stable_prev(CPU2) ...... ......
* prev = CPU2
* CPU2->next = NULL
* ...... ...... ......
* ...... get_statble_prev(CPU3) ......
* prev = CPU3
* CPU3->next = NULL
* ...... ......
* ...... ......
* try_get_stable_next ......
* while(CPU3->next==NULL)
* loop
* ...... ......
* ...... ......
* ...... ......
* ...... get_stable_next
* next = CPU4->next(CPU5)
* CPU4->next = NULL
* ...... ......
* ...... ......
* ...... ......
* ...... ......
* prev(CPU3)->next = next(CPU5)
* prev(CPU5)->prev = prev(CPU3)
* ...... ......
* ...... ......
* loop end ......
* CPU3->next= CPU5
* next is stable
* ...... ......
* get_stable_next ......
* next = CPU5
* CPU3->next = NULL
* ...... ......
*
* prev(CPU2)->next = next(CPU5)
* prev(CPU5)->prev = prev(CPU2)
*
* End:
* CPU1 ----> CPU2 ----> CPU5
*/
for (;;) {
if (prev->next == node &&
cmpxchg(&prev->next, node, NULL) == node)
break;
/*
* We can only fail the cmpxchg() racing against an unlock(),
* in which case we should observe @node->locked becomming
* true.
*/
if (smp_load_acquire(&node->locked))
return true;
cpu_relax_lowlatency();
/*
* Or we race against a concurrent unqueue()'s step-B, in which
* case its step-C will write us a new @node->prev pointer.
*/
prev = READ_ONCE(node->prev);
}
/*
* Step - B -- stabilize @next
*
* Similar to unlock(), wait for @node->next or move @lock from @node
* back to @prev.
*/
next = osq_wait_next(lock, node, prev);
if (!next)
return false;
/*
* Step - C -- unlink
*
* @prev is stable because its still waiting for a new @prev->next
* pointer, @next is stable because our @node->next pointer is NULL and
* it will wait in Step-A.
*/
WRITE_ONCE(next->prev, prev);
WRITE_ONCE(prev->next, next);
return false;
}
void osq_unlock(struct optimistic_spin_queue *lock)
{
struct optimistic_spin_node *node, *next;
int curr = encode_cpu(smp_processor_id());
/*
* Fast path for the uncontended case.
*/
if (likely(atomic_cmpxchg(&lock->tail, curr, OSQ_UNLOCKED_VAL) == curr))
return;
/*
* Second most likely case.
*/
node = this_cpu_ptr(&osq_node);
next = xchg(&node->next, NULL);
if (next) {
WRITE_ONCE(next->locked, 1);
return;
}
/* 等待next 变成stable */
next = osq_wait_next(lock, node, NULL);
if (next)
/* 通知下一个等待的为 1 */
WRITE_ONCE(next->locked, 1);
}
/*
* Get a stable @node->next pointer, either for unlock() or unqueue() purposes.
* Can return NULL in case we were the last queued and we updated @lock instead.
*/
static inline struct optimistic_spin_node *
osq_wait_next(struct optimistic_spin_queue *lock,
struct optimistic_spin_node *node,
struct optimistic_spin_node *prev)
{
struct optimistic_spin_node *next = NULL;
int curr = encode_cpu(smp_processor_id());
int old;
/*
* If there is a prev node in queue, then the 'old' value will be
* the prev node's CPU #, else it's set to OSQ_UNLOCKED_VAL since if
* we're currently last in queue, then the queue will then become empty.
*/
old = prev ? prev->cpu : OSQ_UNLOCKED_VAL;
for (;;) {
if (atomic_read(&lock->tail) == curr &&
atomic_cmpxchg(&lock->tail, curr, old) == curr) {
/*
* We were the last queued, we moved @lock back. @prev
* will now observe @lock and will complete its
* unlock()/unqueue().
*/
break;
}
/*
* We must xchg() the @node->next value, because if we were to
* leave it in, a concurrent unlock()/unqueue() from
* @node->next might complete Step-A and think its @prev is
* still valid.
*
* If the concurrent unlock()/unqueue() wins the race, we'll
* wait for either @lock to point to us, through its Step-B, or
* wait for a new @node->next from its Step-C.
*/
if (node->next) {
next = xchg(&node->next, NULL);
if (next)
break;
}
cpu_relax_lowlatency();
}
return next;
}